Artificial
Intelligence 3E
foundations of computational agents
10.2 Bayesian Learning
Instead of just choosing the most likely hypothesis, it is typically more useful to use the posterior probability distribution of hypotheses, in what is called Bayesian learning.
Suppose is the set of training examples and a test example has inputs (written as ) and target . The aim is to compute . This is the probability distribution of the target variable given the particular inputs and the examples. The role of a model is to be the assumed generator of the examples. If is a set of disjoint and covering models:
| (10.3) |
The first two equalities follow from the definition of (conditional) probability. The last equality relies on two assumptions: the model includes all the information about the examples that is necessary for a particular prediction, , and the model does not change depending on the inputs of the new example, . Instead of choosing the best model, Bayesian learning relies on model averaging, averaging over the predictions of all the models, where each model is weighted by its posterior probability given the training examples, as in Equation 10.3.
can be computed using Bayes’ rule (Equation 10.1), in terms of the prior , the likelihood , and a normalization term.
A common assumption is that examples are independent and identically distributed (i.i.d.) given model , which means examples and , for , are independent given :
The i.i.d. assumption can be represented as the belief network of Figure 10.1.
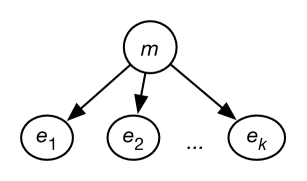
A standard reasoning technique in such a network is to condition on the observed and to either query an unobserved variable, which provides a probabilistic prediction for unseen examples, or query , which provides a distribution over models.
The inference methods of the previous chapter could be used to compute the posterior probabilities. However, the exact methods presented are only applicable when is finite, because they involve enumerating the domains of the variables. However, is usually more complicated (often including real-valued components) than these exact techniques can handle, and approximation methods are required. For some cases, the inference can be exact using special-case algorithms.
The simplest case (Section 10.2.1) is to learn probabilities of a single discrete variable. Bayesian learning can also be used for learning decision trees (Section 10.2.3), learning the structure and probabilities of belief networks (Section 10.4), and more complicated cases.
10.2.1 Learning Probabilities
The simplest learning task is to learn a single Boolean random variable, , with no input features, as in Section 7.2.2. The aim is to learn the posterior distribution of conditioned on the training examples.
Example 10.1.
Consider the problem of predicting the next toss of a thumbtack (drawing pin), where the outcomes and are as follows:
![[Uncaptioned image]](x105.png)
Suppose you tossed a thumbtack a number of times and observed , a particular sequence of instances of and instances of . Assume the tosses are independent, and that occurs with probability . The likelihood is
This is a maximum when the log-likelihood
is a maximum, and the negation of the average log-likelihood, the categorical log loss, is a minimum, which occur when .
Note that if , then is zero, which would indicate that is impossible; similarly, would predict that is impossible, which is an instance of overfitting. A MAP model would also take into account a prior.
Reverend Thomas Bayes [1763] had the insight to treat a probability as a real-valued random variable. For a Boolean variable, , a real-valued variable, , on the interval represents the probability of . Thus, by definition of , and .
Suppose, initially, an agent considers all values in the interval equally likely to be the value of . This can be modeled with the variable having a uniform distribution over the interval . This is the probability density function labeled in Figure 10.2.
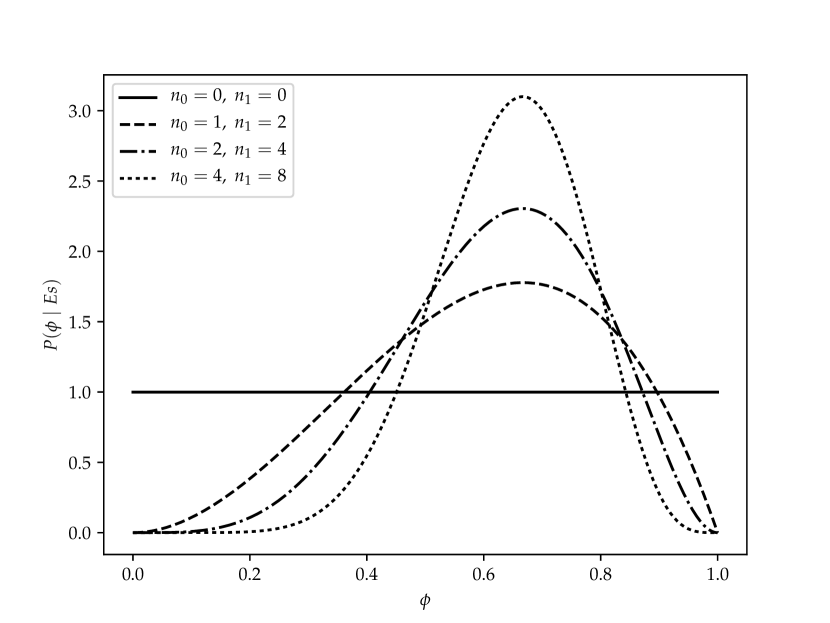
The probability distribution of is updated by conditioning on observed examples. Let the examples be the particular sequence of observations that resulted in occurrences of and occurrences of . Bayes’ rule and the i.i.d. assumption gives
The denominator is a normalizing constant to ensure the area under the curve is 1.
Example 10.2.
Consider the thumbtack of Example 10.1 with a uniform prior.
With a uniform prior and no observations, shown as the line of Figure 10.2, the MAP estimate is undefined – every point is a maximum – and the expected value is 0.5.
When a single heads and no tails is observed, the distribution is a straight line from point to point . The most likely prediction – the MAP estimate – is . The expected value of the resulting distribution is .
When two heads and one tails are observed, the resulting distribution is the line of Figure 10.2. The mode is at and the expected value is .
Figure 10.2 gives some posterior distributions of the variable based on different sample sizes, given a uniform prior. The cases are , , and . Each of these peak at the same place, namely at . More training examples make the curve sharper.
When eight heads and four tails are observed, the mode is at and the expected value is . Notice how the expected value for this case is closer to the empirical proportion of heads in the training data than when , even though the modes are the same empirical proportion.
The distribution of this example is known as the beta distribution; it is parameterized by two counts, and , and a probability . Traditionally, the parameters for the beta distribution are one more than the counts; thus, . The beta distribution is
where is a normalizing constant that ensures the integral over all values is 1. Thus, the uniform distribution on is the beta distribution .
The mode – the value with the maximum probability – of the beta distribution is .
The expected value of the beta distribution is
Thus, the expectation of the beta distribution with a uniform prior gives Laplace smoothing. This shows that Laplace smoothing is optimal for the thought experiment where a probability was selected uniformly in [0,1], training and test data were generated using that probability, and evaluated on test data.
The prior does not need to be the uniform distribution. A common prior is to use a beta distribution for the prior of , such as
corresponding to pseudo-examples with outcome true, and false pseudo-examples. In this case, the posterior probability given examples that consists of a particular sequence of false and true examples is
In this case, the MAP estimate for , the probability of true, is
and the expected value is
This prior has the same form as the posterior; both are described in terms of a ration of counts. A prior that has the same form as a posterior is called a conjugate prior.
Note that is the particular sequence of observations made. If the observation was just that there were a total of occurrences of and occurrences of , you would get a different answer, because you would have to take into account all the possible sequences that could have given this count. This is known as the binomial distribution.
In addition to using the posterior distribution of to derive the expected value, it can be used to answer other questions such as: What is the probability that the posterior probability, , is in the range ? In other words, derive . This is the problem that Bayes [1763] solved in his posthumously published paper. The solution published – although in much more cumbersome notation because calculus had not been invented when it was written – was
This kind of knowledge is used in poll surveys when it may be reported that a survey is correct with an error of at most , times out of , and in a probably approximately correct (PAC) estimate. It guarantees an error at most at least of the time as follows:
-
•
If an agent predicts , the midpoint of the range , it will have error less than or equal to , exactly when the hypothesis is in .
-
•
Let . Then is , so
-
•
choosing the midpoint will result in an error at most in of the time.
Hoeffding’s inequality gives worst-case results, whereas the Bayesian estimate gives the expected number. The worst case provides looser bounds than the expected case.
Categorical Variables
Suppose is a categorical variable with possible values. A distribution over a categorical variable is called a multinomial distribution. The Dirichlet distribution is the generalization of the beta distribution to cover categorical variables. The Dirichlet distribution with two sorts of parameters, the “counts” , and the probability parameters , is
where is the probability of the th outcome (and so ) and is a positive real number and is a normalizing constant that ensures the integral over all the probability values is 1. You can think of as one more than the count of the th outcome, . The Dirichlet distribution looks like Figure 10.2 along each dimension (i.e., as each varies between 0 and 1).
For the Dirichlet distribution, the expected value outcome (averaging over all ) is
The reason that the parameters are one more than the counts in the definitions of the beta and Dirichlet distributions is to make this formula simple.
Suppose an agent must predict a value for with domain , and there are no inputs. The agent starts with a positive pseudocount for each . These counts are chosen before the agent has seen any of the data. Suppose the agent observes training examples with data points having . The probability of is estimated using the expected value
When the dataset is empty (all ), the are used to estimate probabilities. An agent does not have to start with a uniform prior; it could start with any prior distribution. If the agent starts with a prior that is a Dirichlet distribution, its posterior will be a Dirichlet distribution.
Thus, the beta and Dirichlet distributions provide a justification for using pseudocounts for estimating probabilities. A pseudocount of 1 corresponds to Laplace smoothing.
Probabilities from Experts
The use of pseudocounts also gives us a way to combine expert knowledge and data. Often a single agent does not have good data but may have access to multiple experts who have varying levels of expertise and who give different probabilities.
There are a number of problems with obtaining probabilities from experts:
-
•
experts’ reluctance to give an exact probability value that cannot be refined
-
•
representing the uncertainty of a probability estimate
-
•
combining the estimates from multiple experts
-
•
combining expert opinion with actual data.
Rather than expecting experts to give probabilities, the experts can provide counts. Instead of giving a real number for the probability of , an expert gives a pair of numbers as that is interpreted as though the expert had observed occurrences of out of trials. Essentially, the experts provide not only a probability, but also an estimate of the size of the dataset on which their estimate is based.
The counts from different experts can be combined together by adding the components to give the pseudocounts for the system. You should not necessarily believe an expert’s sample size, as people are often overconfident in their abilities. Instead, the size can be estimated taking into account the experiences of the experts. Whereas the ratio between the counts reflects the probability, different levels of confidence are reflected in the absolute values. Consider different ways to represent the probability . The pair , with two positive examples out of three examples, reflects extremely low confidence that would quickly be dominated by data or other experts’ estimates. The pair reflects more confidence – a few examples would not change it much, but tens of examples would. Even hundreds of examples would have little effect on the prior counts of the pair . However, with millions of data points, even these prior counts would have little impact on the resulting probability estimate.
10.2.2 Probabilistic Classifiers
A Bayes classifier is a probabilistic model that is used for supervised learning. A Bayes classifier is based on the idea that the role of a class is to predict the values of features for members of that class. Examples are grouped in classes because they have common values for some of the features. The learning agent learns how the features depend on the class and uses that model to predict the classification of a new example.
The simplest case is the naive Bayes classifier, which makes the independence assumption that the input features are conditionally independent of each other given the classification. The independence of the naive Bayes classifier is embodied in a belief network where the features are the nodes, the target feature (the classification) has no parents, and the target feature is the only parent of each input feature. This belief network requires the probability distributions for the target feature, or class, and for each input feature . For each example, the prediction is computed by conditioning on observed values for the input features and querying the classification. Multiple target variables can be modeled and learned separately.
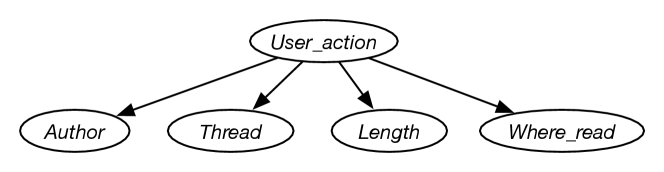
Example 10.3.
Suppose an agent wants to predict the user action given the data of Figure 7.1. For this example, the user action is the classification. The naive Bayes classifier for this example corresponds to the belief network of Figure 10.3. The input features form variables that are children of the classification.
The model of Figure 10.3 corresponds to in Figure 10.1.
Given an example with inputs , Bayes’ rule is used to compute the posterior probability distribution of the example’s classification, :
where the denominator is a normalizing constant to ensure the probabilities sum to 1.
Unlike many other models of supervised learning, the naive Bayes classifier can handle missing data where not all features are observed; the agent conditions on the features that are observed, which assumes the data is missing at random. Naive Bayes is optimal – it makes no independence assumptions beyond missing at random – if only a single is observed. As more of the are observed, the accuracy depends on how independent the are given .
If is Boolean and every is observed, naive Bayes is isomorphic to a logistic regression model; see page 9.3.3 for a derivation. They have identical predictions when the logistic regression weight for is the logarithm of the likelihood ratio, . They are typically learned differently – but don’t need to be – with logistic regression trained to minimize log loss and naive Bayes trained for the conditional probabilities to be the MAP model or the expected value, given a prior.
To learn a classifier, the distributions of and for each input feature can be learned from the data. Each conditional probability distribution may be treated as a separate learning problem for each value of , for example using beta or Dirichlet distributions.
Example 10.4.
Suppose an agent wants to predict the user action given the data of Figure 7.1. For this example, the user action is the classification. The naive Bayes classifier for this example corresponds to the belief network of Figure 10.3. The training examples are used to determine the probabilities required for the belief network.
Suppose the agent uses the empirical frequencies as the probabilities for this example. (Thus, it is not using any pseudocounts.) The maximum likelihood probabilities that can be derived from these data are
Based on these probabilities, the features and have no predictive power because knowing either does not change the probability that the user will read the article.
If the maximum likelihood probabilities are used, some conditional probabilities may be zero. This means that some features become predictive: knowing just one feature value can rule out a category. It is possible that some combinations of observations are impossible, and the classifier will have a divide-by-zero error if these are observed. See Exercise 10.1. This is a problem not necessarily with using a Bayes classifier, but rather with using empirical frequencies as probabilities.
The alternative to using the empirical frequencies is to incorporate pseudocounts. Pseudocounts can be engineered to have desirable behavior, before any data is observed and as more data is acquired.
Example 10.5.
Consider how to learn the probabilities for the help system of Example 9.36, where a helping agent infers what help page a user is interested in based on the words in the user’s query to the help system. Let’s treat the query as a set of words.
The learner must learn . It could start with a pseudocount for each . Pages that are a priori more likely should have a higher pseudocount.
Similarly, the learner needs the probability , the probability that word will be used given the help page is . Because you may want the system to work even before it has received any data, the prior for these probabilities should be carefully designed, taking into account the frequency of words in the language, the words in the help page itself, and other information obtained by experience with other (help) systems.
Assume the following positive counts, which are observed counts plus suitable pseudocounts:
-
•
the number of times was the correct help page
-
•
the total count
-
•
the number of times was the correct help page and word was used in the query.
From these counts an agent can estimate the required probabilities
from which , the posterior distribution of help pages conditioned on the set of words in a user’s query, can be computed; see Example 10.3. It is necessary to use the words not in the query as well as the words in the query. For example, if a help page is about printing, the work “print” may be very likely to be used. The fact that “print” is not in a query is strong evidence that this is not the appropriate help page.
The system could present the help page(s) with the highest probability given the query.
When a user claims to have found the appropriate help page, the counts for that page and the words in the query are updated. Thus, if the user indicates that is the correct page, the counts and are incremented, and for each word used in the query, is incremented. This model does not use information about the wrong page. If the user claims that a page is not the correct page, this information is not used.
The biggest challenge in building such a help system is not in the learning but in acquiring useful data. In particular, users may not know whether they have found the page they were looking for. Thus, users may not know when to stop and provide the feedback from which the system learns. Some users may never be satisfied with a page. Indeed, there may not exist a page they are satisfied with, but that information never gets fed back to the learner. Alternatively, some users may indicate they have found the page they were looking for, even though there may be another page that was more appropriate. In the latter case, the correct page may end up with its counts so low, it is never discovered. See Exercise 10.2.
Although there are some cases where the naive Bayes classifier does not produce good results, it is extremely simple, easy to implement, and often works very well. It is a good method to try for a new problem.
In general, the naive Bayes classifier works well when the independence assumption is appropriate, that is, when the class is a good predictor of the other features and the other features are independent given the class. This may be appropriate for natural kinds, where the classes have evolved because they are useful in distinguishing the objects that humans want to distinguish. Natural kinds are often associated with nouns, such as the class of dogs or the class of chairs.
The naive Bayes classifier can be expanded in a number of ways:
-
•
Some input features could be parents of the classification and some be children. The probability of the classification given its parents could be represented as a decision tree or a squashed linear function or a neural network.
-
•
The children of the classification do not have to be modeled as independent. In a tree-augmented naive Bayes (TAN) network, the children of the class variable are allowed to have zero or one other parents as long as the resulting graph is acyclic. This allows for a simple model that accounts for interdependencies among the children, while retaining efficient inference, as the tree structured in the children has a small treewidth.
-
•
Structure can be incorporated into the class variable. A latent tree model decomposes the class variable into a number of latent variables that are connected together in a tree structure. Each observed variable is a child of one of the latent variables. The latent variables allow a model of the dependence between the observed variables.
10.2.3 Probabilistic Learning of Decision Trees
The previous examples did not need the prior on the structure of models, as all the models were equally complex. However, learning decision trees requires a bias, typically in favor of smaller decision trees. The prior probability provides this bias.
If there are no examples with the same values for the input features but different values for the target feature, there are always multiple decision trees that fit the data perfectly. For every assignment of values that did not appear in the training set, there are decision trees that perfectly fit the training set, and make opposite predictions on the unseen examples. See the no-free-lunch theorem. If there is a possibility of noise, none of the trees that perfectly fit the training set may be the best model.
Example 10.6.
Consider the data of Figure 7.1, where the learner is required to predict the user’s actions.
One possible decision tree is the one given on the left of Figure 7.8. Call this decision tree ; the subscript being the depth. The likelihood of the data is . That is, accurately fits the data.
Another possible decision tree is the one with no internal nodes, and a single leaf that predicts with probability . This is the most likely tree with no internal nodes, given the data. Call this decision tree . The likelihood of the data given this model is
Another possible decision tree is one on the right of Figure 7.8, with one split on and with probabilities on the leaves given by and . Note that is the empirical frequency of among the training set with . Call this decision tree . The likelihood of the data given this model is
These are just three of the possible decision trees. Which is best depends on the prior on trees. The likelihood of the data is multiplied by the prior probability of the decision trees to determine the posterior probability of the decision tree.
10.2.4 Description Length
To find a most likely model given examples – a model that maximizes – you can apply Bayes’ rule, ignore the denominator (which doesn’t depend on ), and so maximize ; see Formula 10.2. Taking the negative of the logarithm (base 2), means you can minimize
This can be interpreted in terms of information theory. The term is the number of bits it takes to describe the data given the model . The term is the number of bits it takes to describe the model. A model that minimizes this sum is a minimum description length (MDL) model. The MDL principle is to choose the model that minimizes the number of bits it takes to describe both the model and the data given the model.
One way to think about the MDL principle is that the aim is to communicate the data as succinctly as possible. To communicate the data, first communicate the model, then communicate the data in terms of the model. The number of bits it takes to communicate the data using a model is the number of bits it takes to communicate the model plus the number of bits it takes to communicate the data in terms of the model.
As the logarithm function is monotonically increasing, the MAP model is the same as the MDL model. Choosing a model with the highest posterior probability is the same as choosing a model with a minimum description length.
The description length provides common units for probabilities and model complexity; they can both be described in terms of bits.
Example 10.7.
In Example 10.6, the definition of the priors on decision trees was left unspecified. The notion of a description length provides a basis for assigning priors to decision trees.
One code for a tree for a Boolean output with Boolean input features might be as follows. A decision tree is either 0 followed by a fixed-length probability, or 1 followed by a bit string representing a condition (an input feature) followed by the tree when the condition is false followed by the tree for when the condition is true. The condition might take , where is the number of input features. The probability could either be a fixed-length bit string, or depend on the data (see below). See Exercise 10.8.
It is often useful to approximate the description length of the model. One way to approximate the description length is to consider just representing the probabilistic parameters of the model. Let be the number of probabilistic parameters of the model . For a decision tree with probabilities at the leaves, is the number of leaves. For a linear function or a neural network, is the number of numerical parameters.
Suppose is the number of training examples. There are at most different probabilities the model needs to distinguish, because that probability is derived from the counts, and there can be from 0 to examples with a particular value true in the dataset. It takes bits to distinguish these probabilities. Thus, the problem of finding the MDL model can be approximated by minimizing
This value is the Bayesian information criteria (BIC) score.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.