Artificial
Intelligence 3E
foundations of computational agents
9.1 Probability
To make a good decision, an agent cannot simply assume what the world is like and act according to that assumption. It must consider multiple hypotheses when making a decision, and not just act on the most likely prediction. Consider the following example.
Example 9.1.
Many people consider it sensible to wear a seat belt when traveling in a car because, in an accident, wearing a seat belt reduces the risk of serious injury. However, consider an agent that commits to assumptions and bases its decision on these assumptions. If the agent assumes it will not have an accident, it will not bother with the inconvenience of wearing a seat belt. If it assumes it will have an accident, it will not go out. In neither case would it wear a seat belt! A more intelligent agent may wear a seat belt because the inconvenience of wearing a seat belt is far outweighed by the increased risk of injury or death if it has an accident. It does not stay at home too worried about an accident to go out; the benefits of being mobile, even with the risk of an accident, outweigh the benefits of the extremely cautious approach of never going out. The decisions of whether to go out and whether to wear a seat belt depend on the likelihood of having an accident, how much a seat belt helps in an accident, the inconvenience of wearing a seat belt, and how important it is to go out. The various trade-offs may be different for different agents. Some people do not wear seat belts, and some people do not go in cars because of the risk of accident.
Reasoning with uncertainty has been studied in the fields of probability theory and decision theory. Probability is the calculus needed for gambling. When an agent makes decisions and is uncertain about the outcomes of its actions, it is gambling on the outcomes. However, unlike a gambler at the casino, an agent that has to survive in the real world cannot opt out and decide not to gamble; whatever it does – including doing nothing – involves uncertainty and risk. If it does not take the probabilities of possible outcomes into account, it will eventually lose at gambling to an agent that does. This does not mean, however, that making the best decision guarantees a win.
Probability is the calculus of belief; probability theory tells us how to update beliefs based on new information. When an agent doesn’t have any information about the particular situation; it will still have beliefs. The belief of an agent before it observes anything is its prior probability. As it discovers information – typically by observing the environment – it updates its beliefs, giving a posterior probability.
The view of probability as a measure of belief is known as Bayesian probability or subjective probability. The term subjective here means “belonging to the subject” (as opposed to subjective meaning arbitrary). Different agents may have different information, and so different beliefs.
Assume that the uncertainty is epistemological – pertaining to an agent’s beliefs about the world – rather than ontological – how the world is. For example, if you are told that someone is very tall, you know they have some height but you only have vague knowledge about the actual value of their height.
Belief in some proposition, , is measured in terms of a number between and . The probability of is means that is believed to be definitely false (no new evidence will shift that belief), and the probability of is means that is believed to be definitely true. Using and is purely a convention; you could just as well use 0 and 100. If an agent’s probability of is greater than zero and less than one, this does not mean that is true to some degree but rather that the agent is ignorant of whether is true or false. The probability reflects the agent’s ignorance.
9.1.1 Semantics of Probability
The semantics is defined in terms of possible worlds, each of which is one way the world could be. An omniscient agent knows which world is the true world, but real agents are not omniscient.
A random variable (or just variable) is a function on worlds. Given a world, it returns a value. The set of values a random variable could return is the domain of the variable.
For example, a variable with domain might be true in worlds where the patient under consideration coughs and false in worlds where the patient doesn’t cough. The variable might be a random variable whose value might be the distance (in centimeters) of the agent from the wall closest to it.
Variables are written starting with an uppercase letter. A discrete variable has a domain that is a finite or countable set. A binary variable is a variable where the domain has two values. A Boolean variable is a binary variable with domain . The assignment of true to a Boolean variable is written as the lower-case variant of the variable (e.g., is written as and is ).
A primitive proposition is an assignment of a value to a variable, or an inequality between a variable and a value, or between variables (e.g., , , or ). A primitive proposition is true in a possible world whenever that condition holds in the world. Propositions are built from primitive propositions using logical connectives. A proposition is either true or false in a world.
A probability measure is a function from sets of worlds into the nonnegative real numbers that satisfies two constraints:
-
•
if and are disjoint sets of worlds (they have no elements in common), then
-
•
where is the set of all possible worlds.
These should not be controversial. For example, the number of people in two groups of people is the sum of the number in each group if the groups don’t have any members in common. The second constraint is just by convention; we could have chosen any other value.
The probability of proposition , written , is the measure of the set of possible worlds in which is true. That is,
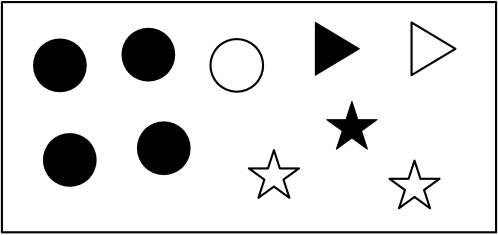
Example 9.2.
Consider the ten possible worlds of Figure 9.1, with Boolean variable and with variable with domain . Each world is defined by its shape, whether it’s filled, and its position. Suppose the measure of each singleton set of worlds is . Then , as there are five circles and , as there are four unfilled shapes. (where “” means “and”), as there is only one unfilled circle.
If is a random variable, a probability distribution, , over is a function from the domain of into the real numbers such that, given a value , is the probability of the proposition . A probability distribution over a set of variables is a function from the values of those variables into a probability. For example, is a probability distribution over and such that , where and , has the value , where is the proposition representing the conjunction (and) of the assignments to the variables, and is the function on propositions defined above. Whether refers to a function on propositions or a probability distribution should be clear from the context.
If are all of the random variables, an assignment to those random variables corresponds to a world, and the probability of the proposition defining a world is equal to the probability of the world. The distribution over all worlds, , is called the joint probability distribution.
Beyond Finitely Many Worlds
The definition of probability is straightforward when there are only finitely many worlds. When there are infinitely many worlds, there are some technical issues that need to be confronted.
There are infinitely many worlds when
-
•
the domain of a variable is infinite, for example, the domain of a variable might be the set of nonnegative real numbers or
-
•
there are infinitely many variables, for example, there might be a variable for the location of a robot for every millisecond from now infinitely far into the future.
When there are infinitely many worlds there are uncountably many sets of worlds, which is more than can be described with a language with finite sentences. We do not need to define the measure for all sets of worlds, just those that can be defined by logical formulas. This is the basis for the definition of a -algebra used in many probability texts.
For variables with continuous domains, the probability of can be zero for all , even though the probability of is positive for . For variables with real-valued domains, a probability density function, written as , is a function from reals into nonnegative reals that integrates to . The probability that a real-valued variable has value between and is
A parametric distribution is one where the probability or density function is described by a formula with free parameters. Not all distributions can be described by formulas, or any finite representation. Sometimes statisticians use the term parametric to mean a distribution described using a fixed, finite number of parameters. A nonparametric distribution is one where the number of parameters is not fixed, such as in a decision tree. (Oddly, nonparametric typically means “many parameters”.)
An alternative is to consider discretization of continuous variables. For example, only consider height to the nearest centimeter or micron, and only consider heights up to some finite number (e.g., a kilometer). Or only consider the location of the robot for a millennium. With finitely many variables, there are only finitely many worlds if the variables are discretized. A challenge is to define representations that work for any (fine enough) discretization.
It is common to work with a parametric distribution when the solutions can be computed analytically and where there is theoretical justification for some particular distribution or the parametric distribution is close enough.
9.1.2 Conditional Probability
Probability is a measure of belief. Beliefs need to be updated when new evidence is observed.
The measure of belief in proposition given proposition is called the conditional probability of given , written .
A proposition representing the conjunction of all of the agent’s observations of the world is called evidence. Given evidence , the conditional probability is the agent’s posterior probability of . The probability is the prior probability of and is the same as because it is the probability before the agent has observed anything.
The evidence used for the posterior probability is everything the agent observes about a particular situation. Everything observed, and not just a few select observations, must be conditioned on to obtain the correct posterior probability.
Example 9.3.
For the diagnostic agent, the prior probability distribution over possible diseases is used before the diagnostic agent finds out about the particular patient. Evidence is obtained through discussions with the patient, observing symptoms, and the results of lab tests. Essentially, any information that the diagnostic agent finds out about the patient is evidence. The agent updates its probability to reflect the new evidence in order to make informed decisions.
Example 9.4.
The information that the delivery robot receives from its sensors is its evidence. When sensors are noisy, the evidence is what is known, such as the particular pattern received by the sensor, not that there is a person in front of the robot. The robot could be mistaken about what is in the world but it knows what information it received.
Semantics of Conditional Probability
Evidence , where is a proposition, will rule out all possible worlds that are incompatible with . Like the definition of logical consequence, the given proposition selects the possible worlds in which is true.
Evidence induces a new measure, , over sets of worlds. Any set of worlds which all have false has measure in . The measure of a set of worlds for which is true in all of them is its measure in multiplied by a constant:
where is a constant (that depends on ) to ensure that is a proper measure.
For to be a probability measure over worlds for each :
Therefore, . Thus, the conditional probability is only defined if . This is reasonable, as if , is impossible.
The conditional probability of proposition given evidence is the sum of the conditional probabilities of the possible worlds in which is true. That is:
The last form above is typically given as the definition of conditional probability. Here we have derived it as a consequence of a more basic definition. This more basic definition is used when designing algorithms; set the assignments inconsistent with the observations to have probability zero, and normalize at the end.
Example 9.5.
As in Example 9.2, consider the worlds of Figure 9.1, with each singleton set having a measure of 0.1. Given the evidence , only four worlds have a nonzero measure, with
A conditional probability distribution, written where and are variables or sets of variables, is a function of the variables: given a value for and a value for , it gives the value , where the latter is the conditional probability of the propositions.
The definition of conditional probability allows the decomposition of a conjunction into a product of conditional probabilities. The definition of conditional probability gives . Repeated application of this product can be used to derive the chain rule:
where the base case is , the empty conjunction being true.
Bayes’ Rule
An agent using probability updates its belief when it observes new evidence. A new piece of evidence is conjoined to the old evidence to form the complete set of evidence. Bayes’ rule specifies how an agent should update its belief in a proposition based on a new piece of evidence.
Suppose an agent has a current belief in proposition based on evidence already observed, given by , and subsequently observes . Its new belief in is . Bayes’ rule tells us how to update the agent’s belief in hypothesis as new evidence arrives.
Proposition 9.1.
(Bayes’ rule) As long as :
This is often written with the background knowledge implicit. In this case, if , then
is the likelihood and is the prior probability of the hypothesis . Bayes’ rule states that the posterior probability is proportional to the likelihood times the prior.
Proof.
The commutativity of conjunction means that is equivalent to , and so they have the same probability given . Using the rule for multiplication in two different ways:
The theorem follows from dividing the right-hand sides by , which is not 0 by assumption. ∎
Generally, one of or is much easier to estimate than the other. Bayes’ rule is used to compute one from the other.
Example 9.6.
In medical diagnosis, the doctor observes a patient’s symptoms, and would like to know the likely diseases. Thus the doctor would like . This is difficult to assess as it depends on the context (e.g., some diseases are more prevalent in hospitals). It is typically easier to assess because how the disease gives rise to the symptoms is typically less context dependent. These two are related by Bayes’ rule, where the prior probability of the disease, , reflects the context.
Example 9.7.
The diagnostic assistant may need to know whether the light switch of Figure 1.6 is broken or not. You would expect that the electrician who installed the light switch in the past would not know if it is broken now, but would be able to specify how the output of a switch is a function of whether there is power coming into the switch, the switch position, and the status of the switch (whether it is working, shorted, installed upside-down, etc.). The prior probability for the switch being broken depends on the maker of the switch and how old it is. Bayes’ rule lets an agent infer the status of the switch given the prior and the evidence.
9.1.3 Expected Values
The expected value of a numerical random variable (one whose domain is the real numbers or a subset of the reals) is the variable’s weighted average value, where sets of worlds with higher probability have higher weight.
Let be a numerical random variable. The expected value of , written , with respect to probability is
when the domain is is finite or countable. When the domain is continuous, the sum becomes an integral.
One special case is if is a proposition, treating as 1 and as 0, where .
Example 9.8.
In an electrical domain, if is the number of switches broken:
would give the expected number of broken switches given by probability distribution . If the world acted according to the probability distribution , this would give the long-run average number of broken switches. If there were three switches, each with a probability of of being broken independently of the others, the expected number of broken switches is
where is the probability that no switches are broken, is the probability that one switch is broken, which is multiplied by 3 as there are three ways that one switch can be broken.
In a manner analogous to the semantic definition of conditional probability, the conditional expected value of conditioned on evidence , written , is
Example 9.9.
The expected number of broken switches given that light is not lit is given by
This is obtained by averaging the number of broken switches over all of the worlds in which light is not lit.
If a variable is Boolean, with true represented as 1 and false as 0, the expected value is the probability of the variable. Thus any algorithms for expected values can also be used to compute probabilities, and any theorems about expected values are also directly applicable to probabilities.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.