Artificial
Intelligence 3E
foundations of computational agents
9.5 Exact Probabilistic Inference
The task of probabilistic inference is to compute the probability of a query variable given evidence , where is a conjunction of assignments of values to some of the variables; that is, to compute . This is the task that is needed for decision making.
Given evidence , and query variable or variables , the problem of computing the posterior distribution on can be reduced to the problem of computing the probability of conjunctions, using the definition of conditioning:
| (9.4) |
where means summing over all of the values of , which is called marginalizing and is an abbreviation for , where is the proposition that is true when has value .
To compute the probability of a product, first introduce all of the other variables. With all of the variables, the definition of a belief network is used to decompose the resulting joint probability into a product of factors.
Suppose is the set of all variables in the belief network and the evidence is , where .
Suppose is a total ordering of the variables in the belief network other than the observed variables, , and the query variable, . That is:
The probability of conjoined with the evidence is
where the subscript means that the observed variables are set to their observed values.
Once all of the variables are modeled, the definition of a belief network, Equation 9.1, shows how to decompose the joint probability:
where is the set of parents of variable .
So
| (9.5) |
The belief-network inference problem is thus reduced to a problem of summing out a set of variables from a product of factors.
Naive Search-Based Algorithm
The naive search-based algorithm shown in Figure 9.9 computes Equation 9.5 from the outside-in. The algorithm is similar to the search-based algorithm for constraint satisfaction problems (see Figure 4.1).
The algorithm takes in a context, , an assignment of values to some of the variables, and a set, , of factors. The aim is to compute the value of the product of the factors, evaluated with the assignment , after all of the variables not in the context are summed out. Initially the context is usually the observations and an assignment of a value to the query variable, and the factors are the conditional probabilities of a belief network.
In this algorithm, the function returns the set of variables in a context or set of factors, so is the set of variables assigned in and is the set of all variables that appear in any factor in . Thus, is the set of variables that appear in factors that are not assigned in the context. The algorithm returns the value of the product of the factors with all of these variables summed out. This is the probability of the context, given the model specified by the factors.
If there are no factors, the probability is 1. Factors are evaluated as soon as they can be. A factor on a set of variables can be evaluated when all of the variables in the factor are assigned in the context. Some representations of factors, such as decision trees, may be able to be evaluated before all of the variables are assigned. The function returns the value of factor in ; it is only called when it can return a value.
If neither of the previous conditions arise, the algorithm selects a variable and branches on it, summing the values. This is marginalizing the selected variable. Which variable is selected does not affect the correctness of the algorithm, but may affect the efficiency.
Exploiting Independence in Inference
The naive search-based algorithm evaluates the sum of Equation 9.5 directly. However, it is possible to do much better.
The distribution law specifies that a sum of products, such as , can be simplified by distributing out the common factors (here ), which results in . The resulting form is more efficient to compute, because it has only one addition and one multiplication. Distributing out common factors is the essence of the efficient exact algorithms. The elements multiplied together are called “factors” because of the use of the term in algebra.

Example 9.22.
Consider the simple chain belief network of Figure 9.10. Suppose you want to compute , the probability of with no observations; the denominator of Equation 9.4 is 1, so let’s ignore that. The variable order , results in the factorization
Consider the rightmost sum (). The left two terms do not include and can be distributed out of that sum, giving
Similarly, can be distributed out of , giving
The search-based algorithms, described below, start at the leftmost sum and sum the values. Variable elimination [see Section 9.5.2] is the dynamic programming variant that creates factors from the inside-out; in this case creating an explicit representation for , which is multiplied by , and then is summed out, and so on.
You could choose a different ordering of the variables, which can result in a different factorization. For example, the variable order gives
Example 9.23.
Consider the query in the simple chain belief network of Figure 9.10. Let’s write as . Equation 9.4 gives
Computing with the variable order gives
Distributing the factors out of the sums gives
This gives two independent problems that can be solved separately. Note that, in this case, the variable order gives the same factorization.
9.5.1 Recursive Conditioning
Recursive conditioning is one of the most efficient exact algorithms. It adds two features to the naive search-based inference algorithm of Figure 9.9, namely caching and recognizing subproblems that can be solved independently. The motivation for this can be seen in the following two examples.
Example 9.24.
Consider the chain belief network of Figure 9.10 with the last factorization of Example 9.22. First splitting on , then , , , results in the tree of Figure 9.11(a). In general, you need to split on the values of the query variable to compute the normalizing constant; while it is not necessary here (because there is no evidence, it must be 1), we show it anyway.
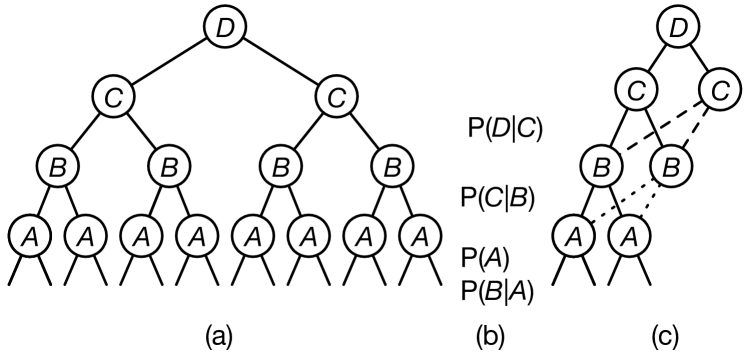
The left branch is for the variable having value false, and the right branch for the variable having value true.
Part (b) of the figure shows the stage where each factor can be evaluated. can be evaluated when and are assigned values. can be evaluated when , , and have been assigned values. For this variable ordering, all variables need to be split before and can be evaluated.
Consider the first recursive call after and have been assigned false, and has been evaluated:
Notice that the factors do not involve , and so this call will have the same value as when the context is .
Recursive conditioning “forgets” , and stores the computed value for
in a cache (a dictionary), and then retrieves that value for the case.
Similarly, after , , and have been assigned a value, the factors are , which will give the same values for as for . Again, recursive conditioning saves the result of in a cache and retrieves that value for the other value of .
This results in the search space of Figure 9.11(c), where the dashed lines indicate a cache lookup.
Example 9.25.
Consider the query for the belief network in Example 9.23. The assigned value, , is given as the initial context. After is assigned a value (which is needed for the denominator of Equation 9.4), the naive search algorithm has the recursive call
This can be decomposed into two independent problems, one using the factors , which has the same value independently of the assignment to , and the other for the factors , which has the same value independently of the assignment to . These factors only have in common, which has been assigned a value in the context.
Thus, this call can be decomposed into the product:
The recursive conditioning algorithm is shown in Figure 9.12.
The function returns the set of variables, as described previously for the naive algorithm.
The cache is a global dictionary that can be reused through recursive calls. It remembers what has already been computed. The keys are pairs. In order to cover the base case, the cache is initialized to have value 1 for the key .
The first condition (line 7) is to check whether the answer has already been computed and stored in the cache. If it has, the stored value is returned. Note that because of the initialization of the cache, this can replace the base case for the naive search.
The second condition (line 9) checks whether there are variables in the context that are not in any factors, and “forgets” them. This is needed so that the caching works properly, as in Example 9.24.
The third condition (line 11) checks whether some factors can be evaluated in the given context. If so, these factors are evaluated and removed from the factors of the recursive call.
The fourth condition (line 13) checks whether the problem can be split into independent parts that can be solved separately and multiplied. Here is the disjoint union, where means that non-empty sets and have no element in common and together contain all of the elements of . Thus, and are a partition of . If all of the variables in common are assigned in the context, the problem can be decomposed into two independent problems. The algorithm could, alternatively, split into multiple nonempty sets of factors that have no unassigned variables in any pair. They would then be the connected components, where the two factors are connected if they both contain a variable that is not assigned in the context. If there are more than two connected components, the algorithm of Figure 9.12 would find the connected components in recursive calls. Note that the subsequent recursive calls typically result in forgetting the variables that are only in the other partition, so it does not need to be done explicitly here.
If none of the other conditions hold (line 15), the algorithm branches. It selects a variable, and sums over all of the values of this variable. Which variable is selected does not affect the result, but can affect the efficiency. Finding the optimal variable to select is an NP-hard problem. Often the algorithm is given a split-order of variables in the order they should be branched on. The algorithm saves the computed result in the cache.
Examples of the application of recursive conditioning are given in Example 9.24 and Example 9.25.
Example 9.26.
Consider Example 9.13 with the query
The initial call (using abbreviated names, and lower-case letters for true value) for the case is
can be evaluated. If it then splits on , the call is
At this stage can be evaluated, and then is not in the remaining factors, so can be forgotten in the context. If it then splits on , the call is
Then can be evaluated, and forgotten. Splitting on results in the call
All of the factors can be evaluated, and so this call returns the value .
The search continues; where the variables are forgotten, the cache is used to look up values rather than computing them. This can be summarized as
| Variable Split on | Factors Evaluated | Forgotten |
|---|---|---|
| , , |
Different variable orderings can result in quite different evaluations, for example, for the same query , for the splitting order , , , :
| Variable Split on | Factors Evaluated | Forgotten |
|---|---|---|
| , | ||
| , | ||
| , |
If was split before and , there are two independent subproblems that can be solved separately; subproblem 1 involving and subproblem 2 involving :
| Variable Split on | Factors Evaluated | Forgotten |
|---|---|---|
| subproblem 1: | ||
| , , | , | |
| subproblem 2: | ||
| , | , | |
The solutions to the subproblems are multiplied.
Some of the conditions checked in Figure 9.12 only depend on the variables in the context, and not on the values of the variables. The results of these conditions can be precomputed and looked up during the search, saving a lot of time.
Some representations of factors (e.g., tables or logistic regression) require all variables to be assigned before they can be evaluated, whereas other representations (e.g., decision trees or weighted logical formula) can often be evaluated before all variables involved have been assigned values. To exploit this short-circuiting effectively, there needs to be good indexing to determine which factors can be evaluated.
9.5.2 Variable Elimination for Belief Networks
Variable elimination (VE) is the dynamic programming variant of recursive conditioning. Consider the decomposition of probability of the query and the evidence (Equation 9.5, reproduced here):
VE carries out the rightmost sum, here first, eliminating , producing an explicit representation of the resulting factor. The resulting factorization then contains one fewer variables. This can be repeated until there is an explicit representation of . The resulting factor is a function just of ; given a value for , it evaluates to a number that is the probability of the evidence conjoined with the value for . The conditional probability can be obtained by normalization (dividing each value by the sum of the values).
To compute the posterior distribution of a query variable given observations:
-
1.
Construct a factor for each conditional probability distribution.
-
2.
Eliminate each of the non-query variables:
-
•
if the variable is observed, its value is set to the observed value in each of the factors in which the variable appears
-
•
otherwise, the variable is summed out.
To sum out a variable from a product of factors, first partition the factors into those not containing , say , and those containing , ; then distribute the common factors out of the sum:
Variable elimination explicitly constructs a representation (in terms of a multidimensional array, a tree, or a set of rules) of the rightmost factor. We have then simplified the problem to have one fewer variable.
-
•
-
3.
Multiply the remaining factors and normalize.
Figure 9.13 gives pseudocode for the VE algorithm. The elimination ordering could be given a priori or computed on the fly. This algorithm assigns the values to the observations as part of the elimination. It is worthwhile to select observed variables first in the elimination ordering, because eliminating these simplifies the problem.
This algorithm assumes that the query variable is not observed. If it is observed to have a particular value, its posterior probability is just 1 for the observed value and 0 for the other values.
Example 9.27.
Consider Example 9.13 with the query
Suppose it first eliminates the observed variables, and . This created a factor for which is just a function of ; call it . Given a value for , this evaluates to a number. becomes a factor .
Suppose is next in the elimination ordering. To eliminate , collect all of the factors containing , namely , , and , and replace them with an explicit representation of the resulting factor. This factor is on and as these are the other variables in the factors being multiplied. Call it :
We explicitly store a number for each value for and . For example, , has value
At this stage, contains the factors
Suppose is eliminated next. VE multiplies the factors containing and sums out from the product, giving a factor, call it :
then contains the factors
Eliminating results in the factor
The posterior distribution over is given by
Note that the denominator is the prior probability of the evidence, namely .
Example 9.28.
Consider the same network as in the previous example but with the query
When is eliminated, the factor becomes a factor of no variables; it is just a number, .
Suppose is eliminated next. It is in one factor, which represents . Summing over all of the values of gives a factor on , all of whose values are 1. This is because for any value of .
If is eliminated next, a factor that is all 1 is multiplied by a factor representing and is summed out. This, again, results in a factor all of whose values are 1.
Similarly, eliminating results in a factor of no variables, whose value is . Note that even if smoke had also been observed, eliminating would result in a factor of no variables, which would not affect the posterior distribution on .
Eventually, there is only the factor on that represents its posterior probability and a constant factor that will cancel in the normalization.
9.5.3 Exploiting Structure and Compilation
When the ordering of the splits in recursive conditioning is the reverse of the elimination ordering of variable elimination, the two algorithms carry out the same multiplications and additions, and the values stored in the factors of variable elimination are the same numbers as stored in the cache of recursive conditioning. The main differences are:
-
•
Recursive conditioning just evaluates the input factors, whereas variable elimination requires an explicit representation of intermediate factors. This means that recursive conditioning can be used where the conditional probabilities can be treated as black boxes that output a value when enough of their variables are instantiated. Thus, recursive conditioning allows for diverse representations of conditional probabilities, such as presented in Section 9.3.3. This also enables it to exploit structure when all of the variables need not be assigned. For example, in a decision tree representation of a conditional probability, it is possible to evaluate a factor before all values are assigned.
-
•
A straightforward implementation of variable elimination can use a more space-efficient tabular representation of the intermediate factors than a straightforward implementation of the cache in recursive conditioning.
-
•
When there are zeros in a product, there is no need to compute the rest of the product. Zeros arise from constraints where some combination of values to variables is impossible. This is called determinism. Determinism can be incorporated into recursive conditioning in a straightforward way.
-
•
Recursive conditioning can act as an any-space algorithm, which can use any amount of space by just not storing some values in the cache, but instead recomputing them, trading off space for time.
To speed up the inference, variables that are irrelevant to a conditional probability query can be pruned. In particular, any node that has no observed or queried descendants and is itself not observed or queried may be pruned. This may result in a smaller network with fewer factors and variables. For example, to compute , in the running example, the variables , , and may be pruned.
The complexity of the algorithms depends on a measure of complexity of the network. The size of a tabular representation of a factor is exponential in the number of variables in the factor. The treewidth of a network for an elimination ordering is the maximum number of variables in a factor created by variable elimination summing out the variables in the elimination ordering. The treewidth of a belief network is the minimum treewidth over all elimination orderings. The treewidth depends only on the graph structure and is a measure of the sparseness of the graph. The complexity of recursive conditioning and variable elimination is exponential in the treewidth and linear in the number of variables. Finding the elimination ordering with minimum treewidth is NP-hard, but there are some good elimination ordering heuristics, as discussed for CSP VE.
Example 9.29.
Consider the belief network of Figure 9.4. To compute the probability of , the variables and may be pruned, as they have no children and are not observed or queried. Summing out involves multiplying the factors
and results in a factor on and . The treewidth of this belief network is 2; there is an ordering of the variables that only constructs factors of size 1 or 2, and there is no ordering of the variables that has a smaller treewidth.
Many modern exact algorithms compile the network into a secondary structure, by essentially carrying out variable elimination or recursive conditioning symbolically, summing out all of the variables, to produce a probabilistic circuit that just contains the symbolic variables combined by sum and product. The circuit is like Figure 9.11, where the branches in (c) form the sums and the conditional probabilities in (b) are multiplied at the appropriate place, as in the factorization of Example 9.22. The circuit is an arithmetic expression with shared structure. When all variables are summed out, the circuit provides an expensive way to compute the value 1. When some variables are observed, the circuit uses the observed values instead of summing out these variables; the output is the probability of the evidence. When a query variable is then set to a value, the circuit outputs the probability of the evidence and the query variable, from which a conditional probability can be computed. It is possible to compute the posterior probability of all variables with two passes through the circuit, but that is beyond the scope of this book.
Compilation is appropriate when the same belief network is used for many multiple queries, or where observations are added incrementally. Unfortunately, extensive preprocessing, allowing arbitrary sequences of observations and deriving the posterior on each variable, precludes pruning the network. So for each application you need to choose whether you will save more by pruning irrelevant variables for each query or by preprocessing before there are any observations or queries.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.