Artificial
Intelligence 3E
foundations of computational agents
2.3 Designing Agents
2.3.1 Discrete, Continuous, and Hybrid
For discrete time there are only a finite number of time steps between any two times; for example, there is a time point every hundredth of a second, or every day, or there may be time points whenever interesting events occur. An alternative is to assume continuous time that is measured by the real numbers.
Similarly, a feature can be discrete, with a finite or countable number of possible values, or the value can be any real number, in which case the feature is continuous. An example of a continuous value might be latitude, longitude, the distance to a wall, or the amount of fuel left. An example of a discrete value might be the room the robot is in, or whether it is carrying a particular item.
High-level reasoning, as carried out in the higher layers, is often discrete and qualitative, whereas low-level reasoning, as carried out in the lower layers, is often continuous and quantitative (see box). A controller that reasons in terms of both discrete and continuous values is called a hybrid system.
Qualitative versus Quantitative Representations
Much of science and engineering considers quantitative reasoning with numerical quantities, using differential and integral calculus as the main tools. Qualitative reasoning is reasoning, often using logic, about qualitative distinctions rather than numerical values for given parameters.
Qualitative reasoning is important for a number of reasons.
-
•
An agent may not know what the exact values are. For example, for the delivery robot to pour coffee, it may not be able to compute the optimal angle that the coffee pot needs to be tilted, but a simple control rule may suffice to fill the cup to a suitable level.
-
•
The reasoning may be applicable regardless of the quantitative values. For example, you may want a strategy for a robot that works regardless of what loads are placed on the robot, how slippery the floors are, or what the actual charge is of the batteries, as long as they are within some normal operating ranges.
-
•
An agent needs to do qualitative reasoning to determine which quantitative laws are applicable. For example, if the delivery robot is filling a coffee cup, different quantitative formulas are appropriate to determine where the coffee goes when the coffee pot is not tilted enough for coffee to come out, when coffee comes out into a non-full cup, and when the coffee cup is full and the coffee is soaking into the carpet.
Qualitative reasoning uses discrete values, which can take a number of forms:
-
•
Landmarks are values that make qualitative distinctions in the individual being modeled. In the coffee example, some important qualitative distinctions include whether the coffee cup is empty, partially full, or full. These landmark values are all that is needed to predict what happens if the cup is tipped upside down or if coffee is poured into the cup.
-
•
Orders-of-magnitude reasoning involves approximate reasoning that ignores minor distinctions. For example, a partially full coffee cup may be full enough to deliver, half empty, or nearly empty. These fuzzy terms have ill-defined borders.
-
•
Qualitative derivatives indicate whether some value is increasing, decreasing, or staying the same.
A flexible agent needs to do qualitative reasoning before it does quantitative reasoning. For simple agents, the qualitative reasoning is often done at design time, so the agent needs to only do quantitative reasoning online. Sometimes qualitative reasoning is all that is needed. An intelligent agent does not always need to do quantitative reasoning, but sometimes it needs to do both qualitative and quantitative reasoning.
Discrete time means that there is a next time from any time, except perhaps a last time. For continuous time, there is no next time. Continuous time can be modeled by adding time and time intervals, for example adding 4:21 pm and 0.003 seconds gives a new time.
Discrete features with continuous time provide an implicit discretization of time; there can be a next time whenever the state changes. A controller might model what is the next state and when it might occur.
When there is continuous state and continuous time, a controller needs to model how they vary together, which requires differential and integral calculus and is beyond the scope of this book.
2.3.2 Choosing Agent Functions
The definition of an agent function gives a great deal of latitude in the design of agents.
One extreme is for a purely reactive system that bases its actions only on the percepts; in this case, the agent function can have an empty or trivial belief state. The command function in this case is a function from percepts into actions. If sensors are very accurate, one might think that they can be relied on with no memory of the history. For example, a global positioning system (GPS) can locate a phone or robot within about 10 meters. However, it is much easier for a robot to locate itself if the GPS signal is combined with historical information about where it was a second ago, and even better if there is an estimate of the direction and speed of travel. A signal that suggests the robot jumped over a river might then be reconciled with the previous signals, and knowledge of how the robot moves.
At the other extreme, an agent could ignore the percepts and rely on a model of the environment and its memory. The agent can then determine what to do just by reasoning. This approach requires a model of the dynamics of the world and of the initial state. Given the state at one time and the dynamics, the state at the next time can be predicted. This process of maintaining the state by forward prediction is known as dead reckoning. For example, a robot could use a model to maintain its estimate of its position and update the estimate based on its actions. This may be appropriate when the world is fully observable and deterministic. When there are unpredictable changes in the world or when there are noisy actuators (e.g., a wheel slips, the wheel is not of exactly the diameter specified in the model, or acceleration is not instantaneous), the noise accumulates, so that the estimates of position soon become very inaccurate. However, if the model is accurate at some level of detail, it may still be useful. For example, finding a route on a map, which can be seen as a high-level plan, is useful for an agent even if it doesn’t specify all of the details and even if it is sometimes wrong.
A more promising approach is to combine the agent’s prediction of the world state with sensing information. This can take a number of forms:
-
•
If both the noise of forward prediction and sensor noise are modeled, the next belief state can be estimated using Bayes’ rule. This is known as filtering.
-
•
With more complicated sensors such as vision, a model can be used to predict where visual features can be found, and then vision can be used to look for these features close to the predicted location. This makes the vision task much simpler than the case where the agent has no idea where it is, and vision can greatly reduce the errors in position arising from forward prediction alone.
A control problem is separable if the best action can be obtained by first finding the best prediction of the state of the world and then using that prediction to determine the best action. Unfortunately, most control problems are not separable. This means that when the world is partially observable, the agent should consider multiple possible states to determine what to do. An agent could represent a probability distribution over the possible states [see Section 9.6], but this is often difficult to represent for complex domains, and often just a few representative hypotheses are chosen [see Section 9.7.6]. Usually, there is no “best model” of the world that is independent of what the agent will do with the model.
2.3.3 Offline and Online Computation
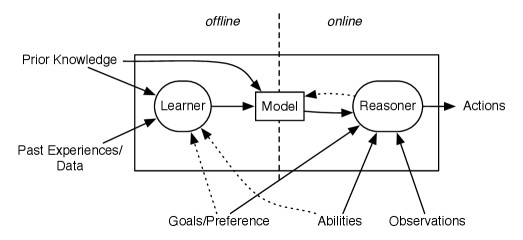
Figure 2.10 shows a refinement of Figure 1.4 showing the online and offline tasks. Offline, a learner creates a model that can be used online. The notion here of a learner is very general, and can include anything that takes data and background knowledge to make the online reasoner more accurate, have more ability, or carry out faster reasoning. The notion of a reasoner is also very general and can range from a simple function to decide actions, to an online learner, to a sophisticated reasoner that deals with all levels of complexity.
The goals and abilities are given offline, online, or both, depending on the agent. For example, a delivery robot could have general goals of keeping the lab clean and not damaging itself or other objects, but it could be given delivery goals at runtime. The online computation can be made simpler and so more efficient if the model is tuned for the particular goals and abilities. This is often not possible when the goals and abilities are only available at runtime.
Offline, before the agent has to act, the agent uses prior knowledge and past experiences (either its own past experiences or data it has been given) to learn (parts of) a model that is useful for acting online. Researchers have traditionally considered the case involving lots of data and very general, or even uninformative, prior knowledge in the field of statistics. The case of rich prior knowledge and little or no data from which to learn has been studied under the umbrella of expert systems. For most non-trivial domains, the agent needs whatever information is available, and so it requires both rich prior knowledge and observations from which to learn.
Online, when the agent is acting, the agent uses its model, its observations of the world, and its goals and abilities to choose what to do and update its belief state. Online, the information about the particular situation becomes available, and the agent has to act. The information includes the observations of the domain and often the preferences or goals. The agent can get observations from sensors, users, and other information sources, such as websites, although it typically does not have access to the domain experts or designers of the system.
An agent typically has much more time for offline computation than for online computation. During online computation it can take advantage of particular goals and particular observations.
For example, a medical diagnosis system offline can acquire knowledge about how diseases and symptoms interact and do some compilation to make inference faster. Online, it deals with a particular patient and needs to act in a timely manner. It can concentrate on the patient’s symptoms and possible related symptoms, ignoring other symptoms, which helps it reason faster.
Online the following roles are involved:
-
•
Users are people who have a need for expertise or have information about individual situations. For example, in a diagnostic system the users might include a patient or a receptionist in a doctor’s office who enters the information. For a travel agent, the user might be a person looking for a holiday or someone providing accommodation or events. Users typically are not experts in the domain of the knowledge base. They often do not know what information is needed by the system. Thus, it is unreasonable to expect them to volunteer everything that is true about a particular situation. A simple and natural interface must be provided because users do not typically understand the internal structure of the system. Human users also only provide observations that are unusual; for example, a patient may specify that they have a bad cough, but not that they didn’t get their arm damaged in an accident.
When users are using the output of the system, they must make informed decisions based on the recommendation of the system; thus, they require an explanation of why any recommendation is appropriate.
-
•
Sensors provide information about the environment. For example, a thermometer is a sensor that can provide the current temperature at the location of the thermometer. Sensors may be more sophisticated, such as a vision sensor. At the lowest level, a vision sensor may simply provide an array of pixels at 50 frames per second for each of red, green, and blue. At a higher level, a vision system may be able to provide information such as the location of particular features, where shoppers are in a store, or whether some particular individual is in the scene. A microphone can be used at a low level of abstraction to detect whether this is a sound and provide a trace of frequencies. At a higher level it may provide a sequence of spoken words.
Sensors come in two main varieties. A passive sensor continuously feeds information to the agent. Passive sensors include thermometers, cameras, and microphones. The designer can typically choose where the sensors are or where they are pointing, but they just feed the agent information. In contrast, an active sensor is controlled or queried for information. Examples of an active sensor include a medical probe able to answer specific questions about a patient or a test given to a student in a tutoring agent. Often, sensors that are passive sensors at lower levels of abstraction can be seen as active sensors at higher levels of abstraction. For example, a camera could be asked whether a particular person is in the room. To do this, it may need to zoom in on the faces in the room, looking for distinguishing features of the person.
-
•
An external knowledge source, such as a website or a database, might be asked questions and can provide the answer for a limited domain. An agent can ask a weather website for the temperature at a particular location or an airline website for the arrival time of a particular flight. The knowledge sources have various protocols and efficiency trade-offs. The interface between an agent and an external knowledge source is called a wrapper. A wrapper translates between the representation the agent uses and the queries the external knowledge source is prepared to handle. Often, wrappers are designed so that the agent is able to ask the same query of multiple knowledge sources. For example, an agent may want to know about airplane arrivals, but different airlines or airports may require very different protocols to access that information. When websites and databases adhere to a common vocabulary, as defined by an ontology, they can be used together because the same symbols have the same meaning. Having the same symbols mean the same thing is called semantic interoperability. When they use different ontologies, there must be mappings between the ontologies to allow them to interoperate.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.