Artificial
Intelligence 3E
foundations of computational agents
16.3 Ontologies and Knowledge Sharing
Building large knowledge-based systems is complex:
-
•
Knowledge often comes from multiple sources, including people, sensors, and the web, which must be integrated. Moreover, these sources may not have the same division of the world. Often knowledge comes from different fields that have their own distinctive terminology and divide the world according to their own needs.
-
•
Systems evolve over time and it is difficult to anticipate all future distinctions that should be made.
-
•
The people involved in designing a knowledge base must choose what individuals and relationships to represent. The world is not divided into individuals; that is something done by intelligent agents to understand the world. Different people involved in a knowledge-based system should agree on this division of the world.
-
•
It is often difficult to remember what your own notation means, let alone to discover what someone else’s notation means. This has two aspects:
-
–
given a symbol used in the computer, determining what it means
-
–
given a concept in someone’s mind, determining what symbol to use. This has three aspects:
-
*
determining whether the concept has already been defined
-
*
if it has been defined, discovering what symbol has been used for it
-
*
if it is not already defined, finding related concepts that it can be defined in terms of.
-
*
-
–
To share and communicate knowledge, it is important to be able to develop a common vocabulary and an agreed-on meaning for that vocabulary.
The Semantic Web
The semantic web is a way to allow machine-interpretable knowledge to be distributed on the World Wide Web. Instead of just serving HTML pages that are meant to be read by humans, websites can also provide information that can be used by computers.
At the most basic level, XML (the Extensible Markup Language) provides a syntax designed to be machine readable, but which is also possible for humans to read. It is a text–based language, where items are tagged in a hierarchical manner. The syntax for XML can be quite complicated, but at the simplest level, the scope of a tag is either in the form , or in the form .
An IRI (internationalized resource identifier) is used to uniquely identify a resource. A resource is anything that can be uniquely identified, including individuals, classes, and properties. Typically, IRIs use the syntax of web addresses (URLs).
RDF (the resource description framework) is a language built on XML, for individual–property–value triples.
RDFS (RDF schema) lets you define resources (classes and properties) in terms of other resources (e.g., using and ). RDFS also lets you restrict the domain and range of properties and provides containers: sets, sequences, and alternatives.
RDF allows sentences in its own language to be reified. This means that it can represent arbitrary logical formulas and so is not decidable in general. Undecidability is not necessarily a bad thing; it just means that you cannot put a bound on the time a computation may take. Logic programs with function symbols and programs in virtually all programming languages are undecidable.
OWL (the web ontology language) is an ontology language for the World Wide Web. It defines some classes and properties with a fixed interpretation that can be used for describing classes, properties, and individuals. It has built-in mechanisms for equality of individuals, classes, and properties, in addition to restricting domains and ranges of properties and other restrictions on properties (e.g., transitivity, cardinality).
There have been some efforts to build large universal ontologies, such as Cyc (www.cyc.com), but the idea of the semantic web is to allow communities to converge on ontologies. Anyone can build an ontology. People who want to develop a knowledge base can use an existing ontology or develop their own ontology, usually building on existing ontologies. Because it is in their interest to have semantic interoperability, companies and individuals should tend to converge on standard ontologies for their domain or to develop mappings from their ontologies to others’ ontologies.
A conceptualization or intended interpretation is a mapping between symbols used in the computer, the vocabulary, and the individuals and relations in the world. It provides a particular abstraction of the world and notation for that abstraction. A conceptualization for small knowledge bases can be in the head of the designer or specified in natural language in the documentation. This informal specification of a conceptualization does not scale to larger systems where the conceptualization must be shared.
In philosophy, ontology is the study of what exists. In AI, an ontology is a specification of the meanings of the symbols in an information system. That is, it is a specification of a conceptualization. It is a specification of what individuals and relationships are assumed to exist and what terminology is used for them. Typically, it specifies what types of individuals will be modeled, specifies what properties will be used, and gives some axioms that restrict the use of that vocabulary.
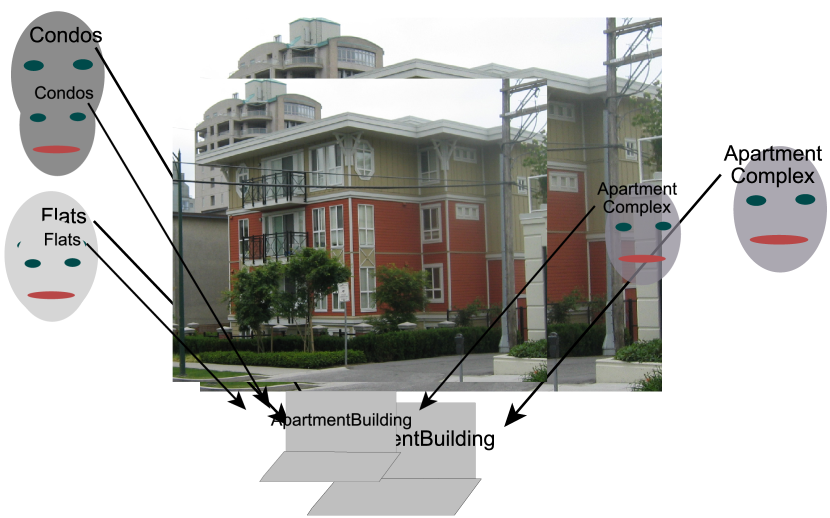
Example 16.13.
An ontology of individuals that could appear on a map could specify that the symbol “ApartmentBuilding” will represent apartment buildings. The ontology will not define an apartment building, but it will describe it well enough so that others can understand the definition. We want other people, who may call such buildings “Condos”, “Flats”, or “Apartment Complex” to be able to find the appropriate symbol in the ontology (see Figure 16.3). That is, given a concept, people want to be able to find the symbol, and, given the symbol, they want to be able to determine what it means.
An ontology may give axioms to restrict the use of some symbols. For example, it may specify that apartment buildings are buildings, which are human-constructed artifacts. It may give some restriction on the size of buildings so that shoeboxes cannot be buildings or that cities cannot be buildings. It may state that a building cannot be at two geographically dispersed locations at the same time (so if you take off some part of the building and move it to a different location, it is no longer a single building). Because apartment buildings are buildings, these restrictions also apply to apartment buildings.
Ontologies are usually written independently of a particular application and often involve a community agreeing on the meanings of symbols. An ontology consists of:
-
•
a vocabulary of the categories of the things (both classes and properties) that a knowledge base may want to represent
-
•
an organization of the categories, for example into an inheritance hierarchy using or (where property is a sub-property of property if implies for all and ), or using Aristotelian definitions, and
-
•
a set of axioms restricting the definition of some of the symbols to better reflect their intended meaning – for example, that some property is transitive, or the domain and range of a property, or restrictions on the number of values a property can take for each individual. Sometimes relationships are defined in terms of other relationships but, ultimately, the relationships are grounded out into primitive relationships that are not actually defined.
An ontology does not specify the individuals not known at design time. For example, an ontology of buildings would typically not include actual buildings. An ontology would specify those individuals that are fixed and should be shared, such as the days of the week, or colors.
Example 16.14.
Consider a trading agent that is designed to find accommodations. Users could use such an agent to describe what accommodation they want. The trading agent could search multiple knowledge bases to find suitable accommodations or to notify users when some appropriate accommodation becomes available. An ontology is required to specify the meaning of the symbols for the user and to allow the knowledge bases to interoperate. It provides the semantic glue to tie together the users’ needs with the knowledge bases.
In such a domain, houses and apartment buildings may both be residential buildings. Although it may be sensible to suggest renting a house or an apartment in an apartment building, it may not be sensible to suggest renting an apartment building to someone who does not actually specify that they want to rent the whole building. A “living unit” could be defined to be the collection of rooms that some people, who are living together, live in. A living unit may be what a rental agency offers to rent. At some stage, the designer may have to decide whether a room for rent in a house is a living unit, or even whether part of a shared room that is rented separately is a living unit. Often the boundary cases – cases that may not be initially anticipated – are not clearly delineated but become better defined as the ontology evolves.
The ontology would not contain descriptions of actual houses or apartments because, at the time the ontology is defined, the designers will not know which houses will be described by the ontology. The ontology will change much slower than the actual available accommodation.
The primary purpose of an ontology is to document what the symbols mean – the mapping between symbols (in a computer) and concepts (in someone’s head). Given a symbol, a person is able to use the ontology to determine what it means. When someone has a concept to be represented, the ontology is used to find the appropriate symbol or to determine that the concept does not exist in the ontology. The secondary purpose, achieved by the use of axioms, is to allow inference or to determine that some combination of values is inconsistent. The main challenge in building an ontology is the organization of the concepts to allow a human to map concepts into symbols in the computer, and to allow a computer to infer useful new knowledge from stated facts.
16.3.1 Description Logic
Modern ontology languages such as OWL are based on description logics. A description logic is used to describe classes, properties, and individuals. One of the main ideas behind a description logic is to separate
-
•
a terminological knowledge base (or TBox), describes the terminology; it defines what the symbols mean
-
•
an assertional knowledge base (or ABox), specifies what is true at some point in time.
Usually, the terminological knowledge base is defined at the design time of the system and defines the ontology, and it only changes as the meaning of the vocabulary changes, which should be relatively rarely. The assertional knowledge base usually contains the knowledge that is situation specific and is only known at run time.
It is typical to use triples to define the assertional knowledge base and a language such as OWL to define the terminological knowledge base.
The web ontology language (OWL) describes domains in terms of
-
•
Individuals – things in the world that is being described (e.g., a particular house or a particular booking may be individuals).
-
•
Classes – sets of individuals. A class is the set of all real or potential things that would be in that class. For example, the class “House” may be the set of all things that would be classified as a house, not just those houses that exist in the domain of interest.
-
•
Properties – used to describe binary relationships between individuals and other individuals or values. A datatype property has values that are primitive data types, such as integers, strings, or dates. For example, “streetName” may be a datatype property between a street and a string. An object property has values that are other individuals. For example, “nextTo” may be a property between two houses, and “onStreet” may be a property between a house and a street.
OWL comes in a few variants that differ in restrictions imposed on the classes and properties, and how efficiently they can be implemented. For example, in OWL-DL a class cannot be an individual or a property, and a property is not an individual. In OWL-Full, the categories of individuals, properties, and classes are not necessarily disjoint. OWL-DL comes in three profiles that are targeted towards particular applications, and do not allow constructs they do not need that would make inference slower. OWL 2 EL is designed for large biohealth ontologies, allowing rich structural descriptions. OWL 2 QL is designed to be the front end of database query languages. OWL 2 RL is a language that is designed for cases where rules are important.
OWL does not make the unique names assumption; two names do not necessarily denote different individuals or different classes. It also does not make the complete knowledge assumption; it does not assume that all the relevant facts have been stated.
are classes, is a property, are individuals, and is an integer. is the number of elements in set .
| Class | Class Contains |
|---|---|
| owl:Thing | all individuals |
| owl:Nothing | no individuals (empty set) |
| owl:ObjectIntersectionOf | individuals in |
| owl:ObjectUnionOf | individuals in |
| owl:ObjectComplementOf | the individuals not in |
| owl:ObjectOneOf | |
| owl:ObjectHasValue | individuals with value on property ; i.e., |
| owl:ObjectAllValuesFrom | individuals with all values in on property ; i.e., |
| owl:ObjectSomeValuesFrom | individuals with some values in on property ; i.e., |
| owl:ObjectMinCardinality | individuals with at least individuals of class related to by ; i.e., |
| owl:ObjectMaxCardinality | individuals with at most individuals of class related to by ; i.e., |
| owl:ObjectHasSelf | individuals such that ; i.e., |
OWL has the following predicates with a fixed interpretation, where are classes, are properties, and are individuals; and are universally quantified variables.
| Statement | Meaning |
|---|---|
| rdf:type | |
| owl:ClassAssertion | |
| rdfs:subClassOf | |
| owl:SubClassOf | |
| rdfs:domain | if then |
| owl:ObjectPropertyDomain | if then |
| rdfs:range | if then |
| owl:ObjectPropertyRange | if then |
| owl:EquivalentClasses | for all |
| owl:DisjointClasses | for all |
| rdfs:subPropertyOf | implies |
| owl:EquivalentObjectProperties | if and only if |
| owl:DisjointObjectProperties | implies not |
| owl:InverseObjectProperties | if and only if |
| owl:SameIndividual | |
| owl:DifferentIndividuals | implies |
| owl:FunctionalObjectProperty | |
| owl:InverseFunctionalObjectProperty | |
| owl:TransitiveObjectProperty | |
| owl:SymmetricObjectProperty | |
| owl:AsymmetricObjectProperty | implies not |
| owl:ReflectiveObjectProperty | for all |
| owl:IrreflectiveObjectProperty | not for all |
Figure 16.4 gives some primitive classes and some class constructors. This figure uses set notation to define the set of individuals in a class. Figure 16.5 gives some primitive predicates of OWL. The owl: prefix is an abbreviation for the standard IRI for OWL.
In these figures, is a triple. OWL defines some terminology that is used to define the meaning of the predicates, rather than any syntax. The predicates can be used with different syntaxes, such as XML, triples, or functional notation.
Example 16.15.
As an example of a class constructor in functional notation:
| ObjectHasValue(country_of_citizenship, Q16) |
is the class containing the citizens of Canada (Q16).
Q113489728 is the class of countries that are members of the Organization for Economic Co-operation and Development (OECD), so
| ObjectSomeValuesFrom(country_of_citizenship, Q113489728) |
is the class of people that are citizens of a country that is a member of the OECD. For people with multiple citizenships, at least one of the countries they are a citizen of has to be an OECD country.
| MinCardinality(2, country_of_citizenship, Q113489728) |
is the class of individuals who are citizens of two or more countries that are members of the OECD.
The class constructors must be used in a statement, for example, to say that some individual is a member of this class or to say that one class is equivalent to some other class.
OWL does not have definite clauses. To say that all of the elements of a set have value for a predicate , we say that is a subset of the set of all things with value for predicate .
Some of OWL and RDF or RDFS statements have the same meaning. For example, rdf:type means the same as owl:ClassAssertion and rdfs:domain means the same as owl:ObjectPropertyDomain for object properties. Some ontologies use both definitions, because the ontologies were developed over long periods of time, with contributors who adopted different conventions.
Example 16.16.
Consider an Aristotelian definition of an apartment building. We can say that an apartment building is a residential building with multiple units and the units are rented. (This is in contrast to a condominium building, where the units are individually sold, or a house, where there is only one unit.) Suppose we have the class that is a subclass of .
The following defines the functional object property , with domain and range :
FunctionalObjectProperty(numberOfunits)
ObjectPropertyDomain(numberOfunits, ResidentialBuilding)
ObjectPropertyRange(numberOfunits,
ObjectOneOf(two, one, moreThanTwo)).
The functional object property with domain and range can be defined similarly.
An apartment building is a where the property has the value and the property has the value . To specify this in OWL, we define the class of things that have value for the property , the class of things that have value for the property , and say that is equivalent to the intersection of these classes. In OWL functional syntax, this is
EquivalentClasses(ApartmentBuilding,
ObjectIntersectionOf(
ResidentialBuilding,
ObjectHasValue(numberOfunits, moreThanTwo),
ObjectHasValue(ownership, rental))).
This definition can be used to answer questions about apartment buildings, such as the ownership and the number of units. Apartment buildings inherit all of the properties of residential buildings.
The previous example did not really define . The system has no idea what ownership actually means. Hopefully, a user will know what it means. Everyone who wants to adopt an ontology should ensure that their use of a property and a class is consistent with other users of the ontology.
There is one property constructor in OWL, owl:ObjectInverseOf, which is the inverse property of ; that is, it is the property such that if and only if . Note that it is only applicable to object properties; datatype properties do not have inverses, because data types cannot be the subject of a triple.
The list of classes and statements in these figures is not complete. There are corresponding datatype classes for datatype properties, where appropriate. For example, owl:DataSomeValuesFrom and owl:EquivalentDataProperties have the same definitions as the corresponding object symbols, but are for datatype properties. There are also other constructs in OWL to define properties, comments, annotations, versioning, and importing other ontologies.
A domain ontology is an ontology about a particular domain of interest. Most existing ontologies are in a narrow domain that people write for specific applications. There are some guidelines that have evolved for writing domain ontologies to enable knowledge sharing:
-
•
If possible, use an existing well-established ontology. This means that your knowledge base will be able to interact with others who use the same ontology.
-
•
If an existing ontology does not exactly match your needs, import it and add to it. Do not start from scratch, because people who have used the existing ontology will have a difficult time also using yours, and others who want to select an ontology will have to choose one or the other. If your ontology includes and improves the other, others who want to adopt an ontology will choose yours, because their application will be able to interact with adopters of either ontology.
-
•
Make sure that your ontology integrates with neighboring ontologies. For example, an ontology about resorts may have to interact with ontologies about food, beaches, recreation activities, and so on. When first designing the ontology, you may not know the full extent of what it needs to interoperate with. Try to make sure that it uses the same terminology as possibly related ontologies for the same things.
-
•
Try to fit in with higher-level ontologies (see below). This will make it much easier for others to integrate their knowledge with yours.
-
•
If you must design a new ontology, consult widely with other potential users. This will make it most useful and most likely to be adopted.
-
•
Follow naming conventions. For example, call a class by the singular name of its members. For example, call a class “Resort” not “Resorts”. Resist the temptation to call it “ResortConcept” (thinking it is only the concept of a resort, not a resort; see the box). When naming classes and properties, think about how they will be used. It sounds better to say that “ is a Resort” than “ is a Resorts”, which is better than “ is a ResortConcept”.
-
•
As a last option, specify the matching between ontologies. Sometimes ontology matching has to be done when ontologies are developed independently. It is best if matching can be avoided; it makes knowledge using the ontologies much more complicated because there are multiple ways to say the same thing.
Classes and Concepts
When defining an ontology, it is tempting to name the classes concepts, because symbols represent concepts: mappings from the internal representation into the object or relations that the symbols represent.
For example, it may be tempting to call the class of unicorns “unicornConcept” because there are no unicorns, only the concept of a unicorn. However, unicorns and the concept of unicorns are very different; one is an animal and one is a subclass of knowledge. A unicorn has four legs and a horn coming out of its head. The concept of a unicorn does not have legs or horns. You would be very surprised if a unicorn appeared in a university lecture about ontologies, but you should not be surprised if the concept of a unicorn appeared. There are no instances of unicorns, but there are many instances of the concept of a unicorn. If you mean a unicorn, you should use the term “unicorn”. If you mean the concept of a unicorn, you should use “concept of a unicorn”. You should not say that a unicorn concept has four legs, because instances of knowledge do not have legs; animals, furniture, and some robots have legs.
As another example, consider a tectonic plate, which is part of the Earth’s crust. The plates are millions of years old. The concept of a plate is less than a hundred years old. Someone can have the concept of a tectonic plate in their head, but they cannot have a tectonic plate in their head. It should be clear that a tectonic plate and the concept of a tectonic plate are very different things, with very different properties. You should not use “concept of a tectonic plate” when you mean “tectonic plate” and vice versa.
Calling objects concepts is a common error in building ontologies. Although you are free to call things by whatever name you want, it is only useful for knowledge sharing if other people adopt your ontology. They will not adopt it if it does not make sense to them.
OWL is at a lower level than most people will want to specify or read. It is designed to be a machine-readable specification. There are many editors that let you edit OWL representation. One example is Protégé (http://protege.stanford.edu/). An ontology editor should support the following:
-
•
It should provide a way for people to input ontologies at the level of abstraction that makes the most sense.
-
•
Given a concept a user wants to use, an ontology editor should facilitate finding the terminology for that concept or determining that there is no corresponding term.
-
•
It should be straightforward for someone to determine the meaning of a term.
-
•
It should be as easy as possible to check that the ontology is correct (i.e., matches the user’s intended interpretation for the terms).
-
•
It should create an ontology that others can use. This means that it should use a standardized language as much as possible.
16.3.2 Top-Level Ontologies
Example 16.16 defines a domain ontology for apartment building that could be used by people who want to write a knowledge base that refers to things that can appear on maps. Each domain ontology implicitly or explicitly assumes a higher-level ontology that it can fit into. The apartment building ontology assumes buildings are defined.
A top-level ontology provides a definition of everything at a very abstract level. The goal of a top-level ontology is to provide a useful categorization on which to base other ontologies. Making it explicit how domain ontologies fit into an upper-level ontology promises to facilitate the integration of these ontologies. The integration of ontologies is necessary to allow applications to refer to multiple knowledge bases, each of which may use different ontologies.
At the top is entity. OWL calls the top of the hierarchy thing. Essentially, everything is an entity.
Some of the high-level properties used to define domain ontologies include
-
•
Concrete or abstract: physical objects and events are concrete, but mathematic objects and times are abstract.
-
•
Continuant or occurrent: A continuant is something that exists at an instant in time and continues to exist through time. Examples include a person, a finger, a country, a smile, the smell of a flower, and an email. When a continuant exists at any time, so do its parts. Continuants maintain their identity through time. An occurrent is something that has temporal parts, for example, a life, infancy, smiling, the opening of a flower, and sending an email. One way to think about the difference is to consider the entity’s parts: a finger is part of a person, but is not part of a life; infancy is part of a life, but is not part of a person. Continuants participate in occurrents. Processes that last through time and events that occur at an instant in time are both occurrents.
An alternative to the continent/occurrent dichotomy is a four-dimensional or perdurant view where objects exist in the space-time, so a person is a trajectory though space and time, and there is no distinction between the person and the life. At any time, a person is a snapshot of the four-dimensional trajectory.
-
•
Dependent or independent: An independent continuant is something that can exist by itself or is part of another entity. For example, a person, a face, a pen, a flower, a country, and the atmosphere are independent continuants. A dependent continuant only exists by virtue of another entity and is not a part of that entity. For example, a smile, the ability to laugh, or the inside of your mouth, or the ownership relation between a person and a phone, can only exist in relation to another object or objects. Note that something that is a part of another object is an independent continuant; for example, while a heart cannot exist without a body, it can be detached from the body and still exist. This is different from a smile; you cannot detach a smile from a cat.
An occurrent that is dependent on an entity is a process or an event. A process is something that happens over time, has temporal parts, and depends on a continuant. For example, Joe’s life has parts such as infancy, childhood, adolescence, and adulthood and involves a continuant, Joe. A holiday, writing an email, and a robot cleaning the lab are all processes. An event is something that happens at an instant, and is often a process boundary. For example, the first goal in the 2022 FIFA World Cup final is an event that happens at the instant the ball crosses the goal line; it could be seen as the end of a process that involves a team.
-
•
Connected or scattered: A living bird is a single connected whole, but a flock of birds is a scattered entity made up of multiple birds. March 2024 is a connected single but Tuesdays from 3:00 to 4:00 GMT is a scattered temporal region.
-
•
Material or immaterial. An independent continuant is either a material entity or an immaterial entity. A material entity has some matter as a part. Material entities are localized in space and can move in space. Examples of material entities are a person, a football team, Mount Everest, and Hurricane Katrina. Immaterial entities are abstract. Examples of immaterial entities are the first email you sent last Monday, a plan, and an experimental protocol. Note that you need a physical embodiment of an email to receive it (e.g., as text on your smartphone or spoken by a speech synthesizer), but the email is not that physical embodiment; a different physical embodiment could still be the same email.
Different categories can be formed by choosing among these dichotomies. A material entity that is a single coherent whole is an object. An object maintains its identity through time even if it gains or loses parts (e.g., a person who loses some hair, a belief, or even a leg, is still the same person). A person, a chair, a cake, or a computer are all objects. The left leg of a person (if it is still attached to the person), a football team, or the equator are not objects. If a robot were asked to find three objects, it would not be reasonable to bring a chair and claim the back, the seat, and the left-front leg are three objects.
Designing a top-level ontology is difficult. It probably will not satisfy everyone. There always seem to be some problematic cases. In particular, boundary cases are often not well specified. However, using a standard top-level ontology should help in connecting ontologies together.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.