Artificial
Intelligence 3E
foundations of computational agents
8.1 Feedforward Neural Networks
There are many different types of neural networks. A feedforward neural network implements a prediction function given inputs as
| (8.1) |
Each function maps a vector (array or list) of values into a vector of values. The function is the th layer. The number of functions composed, , is the depth of the neural network. The last layer, , is the output layer. The other layers are called hidden layers. Sometimes the input, , is called the input layer. Each component of the output vector of a layer is called a unit. The “deep” in deep learning refers to the depth of the network.
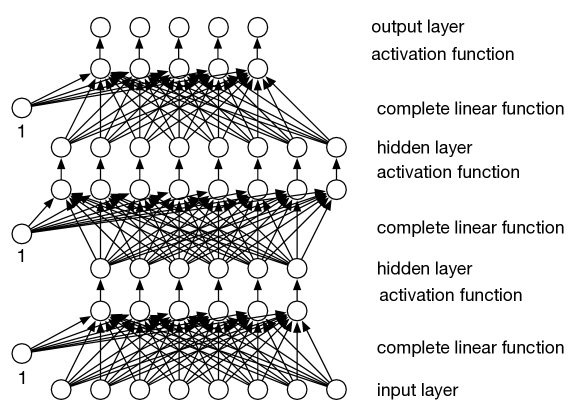
In a feedforward network, each layer is a linear function with learnable parameters of each output given the input, similar to linear or logistic regression, followed by a nonlinear activation function, . The linear function takes a vector of values for the inputs to the layer (and, as in linear regression, an extra constant input that has value “1”), and returns a vector of output values, so that
for a two-dimensional array of weights. The weight associated with the extra 1 input is the bias. There is a weight for each input–output pair of the layer, plus a bias for each output. The outputs of one layer are the inputs to the next. See Figure 8.1.
The activation function for the hidden layers is a nonlinear function. If it is a linear function (or the identity), the layer is redundant as a linear function of a linear function is another linear function. An activation function should be (almost everywhere) differentiable so that methods based on gradient descent work.
A common activation function for hidden layers is the rectified linear unit (ReLU): defined by . That is
has derivative 0 for and 1 for . Although it does not have a derivative for , assume the derivative is 0. If all the hidden layers use ReLU activation, the network implements a piecewise linear function.
The activation function for the output layer depends on the type of the output and the error function (loss) that is being optimized.
-
•
If is real and the average squared loss is optimized, the activation function is typically the identity function: .
-
•
If is Boolean with binary log loss optimized, the activation function is typically the sigmoid: . Sigmoid has a theoretical justification in terms of probability.
-
•
If is categorical, but not binary, and categorical log loss is optimized, the activation function is typically softmax. The output layer has one unit for each value in the domain of .
In each of these choices, the activation function and the loss complement each other to have a simple derivative. For each of these, the derivative of the error is proportional to .

Example 8.1.
Consider the function with three Boolean inputs , , and and where the Boolean target has the value of if is true, and has the value of if is false (see Figure 7.10). This function is not linearly separable (see Example 7.13) and logistic regression fails for a dataset that follows this structure (Example 7.11).
This function can be approximated using a neural network with one hidden layer containing two units. As the target is Boolean, a sigmoid is used for the output.
The function is equivalent to the logical formula . Each of these operations can be represented in terms of rectified linear units or approximated by sigmoids. The first layer can be represented as the function with two outputs, and , defined as
Then is 1 when is true and is 1 when is true, and they are 0 otherwise. The output is , which approximates the function with approximately a error. The resulting two-layer neural network is shown in Figure 8.2.
Neural networks can have multiple real-valued inputs. Non-binary categorical features can be transformed into indicator variables, which results in a one-hot encoding.
The width of a layer is the number of elements in the vector output of the layer. The width of a neural network is the maximum width over all layers. The architectural design of a network includes the depth of the network (number of layers) and the width of each hidden layer. The size of the output and input are usually specified as part of the problem definition. A network with one hidden layer – as long as it is wide enough – can approximate any continuous function on an interval of the reals, or any function of discrete inputs to discrete outputs. The width required may be prohibitively wide, and it is typically better for a network to be deep than be very wide. Lower-level layers can provide useful features to make the upper layers simpler.
8.1.1 Parameter Learning
Backpropagation implements (stochastic) gradient descent for all weights. Recall that stochastic gradient descent involves updating each weight proportionally to , for each example in a batch.
There are two properties of differentiation used in backpropagation.
-
•
Linear rule: the derivative of a linear function, , is given by
so the derivative is the number that is multiplied by in the linear function.
-
•
Chain rule: if is a function of and function , which does not depend on , is applied to , then
where is the derivative of .
Let , the output of the prediction function (Equation 8.1) for example , with input features . The are parametrized by weights. Suppose , which means and . The values for for can be computed with one pass through the nested functions.
Consider a single weight that is used in the definition of . The for do not depend on . The derivative of with respect to weight :
where is the derivative of with respect to its inputs. The expansion can stop at . The last partial derivative is not an instance of the chain rule because is not a function of . Instead, the linear rule is used, where is multiplied by the appropriate component of .
Backpropagation determines the update for every weight with two passes through the network for each example.
-
•
Prediction: given the values on the inputs for each layer, compute a value for the outputs of the layer. That is, the are computed. In the algorithm below, each is stored in a array associated with the layer.
-
•
Back propagate: go backwards through the layers to determine the update of all of the weights of the network (the weights in the linear layers). Going backwards, the for starting from 0 are computed and passed to the lower layers. This input is the error term for a layer, which is combined with the values computed in the prediction pass, to update all of the weights for the layer, and compute the error term for the lower layer.
Storing the intermediate results makes backpropagation a dynamic programming form of (stochastic) gradient descent.
A layer is represented by a linear function and an activation function in the algorithm below. Each function is implemented modularly as a class (in the sense of object-oriented programming) that implements forward prediction and backpropagation for each example, and the updates for the weights after a batch.
The class implements a dense linear function, where each output unit is connected to all input units. The array stores the weights, so the weight for input unit connected to output unit is , and the bias (the weight associated with the implicit input that is always 1) for output is in . The methods and are called for each example. accumulates the gradients for each in , and returns an error term for the lower levels. The method updates the parameters given the gradients of the batch, and resets . The method remembers any information necessary for for each example.
The class for each function implements the methods:
-
•
returns the output values for the input values of vector
-
•
returns vector of input errors, and updates gradients
-
•
updates the weights for a batch
Each class stores and if needed for
Figure 8.3 shows a modular version of backpropagation. The variable is the sequence of possibly parameterized functions that defines the neural network (typically a linear function and an activation function for each layer). Each function is implemented as a class that can carry out the forward and backward passes and remembers any information it needs to.
The first function for the lowest layer has as many inputs as there are input features. For each subsequent function, the number of inputs is the same as the number of outputs of the previous function. The number of outputs of the final function is the number of target features, or the number of values for a (non-binary) categorical output feature.
The pseudocode of Figure 8.3 assumes the type of the output activation function is made to complement the error (loss) function, so that the derivative is proportional to the predicted value minus the actual value. This is true of the identity activation for squared error (Equation 7.1), the sigmoid activation for binary log loss (Equation 7.3), and softmax for categorical log loss. The final activation function, , is used in , but is not implemented as a class. Other combinations of error functions and loss might have a different form; modern tools automate taking derivatives so you do not need to program it directly.
Figure 8.4 shows the pseudocode for two common activation functions. ReLU is typically used for hidden layers in modern deep networks. Sigmoid was common in classical neural networks, and is still used in models such as the long short-term memory network (LSTM).
Mappings to the parameters of Keras and PyTorch, two common deep learning libraries, are presented in Appendix B.2.
Example 8.2.
Consider training the parameters of the network of Figure 8.2 using the “if then else ” data of Figure 7.10(b).
This network is represented by the call to with
In one run with 10,000 epochs, learning rate of 0.01, and batch size 8 (including all examples in a batch), the weights learned gave the network represented by the following equations (to three significant digits), where and are the hidden units:
This has learned to approximate the function to 1% error in the worst case. The prediction with the largest log loss is the prediction of for the example with , which should be 1.
Different runs can give quite different weights. For small examples like this, you could try to interpret the target. In this case (very approximately) is positive unless and is only large when . Notice that, even for a simple example like this, it is difficult to explain (or understand) why it works. Easy-to-explain weights, like Example 8.1, do not arise in practice. Realistic problems have too many parameters to even try to interpret them.
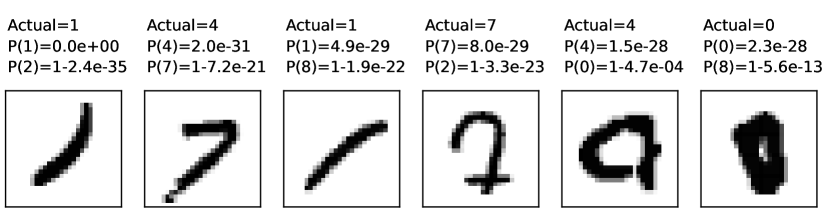
The most uncertain (closest to 0.5) incorrect predictions for the training set

and for the test set:

The predictions with highest log loss for the training set are as follows (where indicates the number is less than machine precision for the GPU (), and because most of the mode predictions are 1.0 to machine precision, they are written as , for the given ):
and for the test set:
Example 8.3.
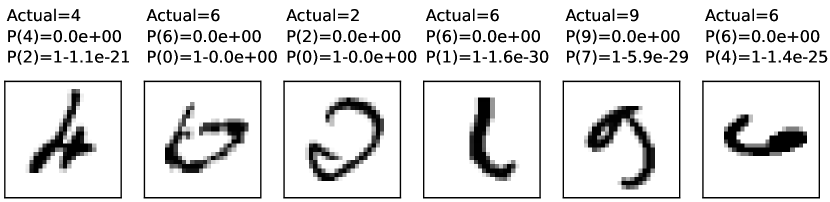
MNIST (Modified National Institute of Standards and Technology database) is a dataset of grayscale images of hand-written digits. Each image consists of a grid of pixels, where each pixel is an integer in the range specifying its intensity. Some examples are shown in Figure 8.5. There are 60,000 training images and 10,000 test images. MNIST has been used for many perceptual learning case studies.
This was trained with a network with 784 input units (one for each pixel), and one hidden layer containing 512 units with ReLU activation. There are 10 output units, one for each digit, combined with a softmax. It was optimized for categorical cross entropy, and trained for five epochs (each example was used five times, on average, in the training), with a batch size of 128.
After training, the model has a training log loss (base ) of 0.21, with an accuracy of 98.4% (the mode is the correct label). On the test set the log loss is 0.68, with an accuracy of 97.0%. If trained for more epochs, the fit to the training data gets better, but on the test set, the log loss becomes much worse and accuracy improves to test 97.7% after 15 more epochs. This is run with the default parameters of Keras; different runs might have different errors, and different extreme examples.
Often, insights can be obtained by looking at the incorrect predictions. Figure 8.5 shows some of the predictions for the images in the training set and the test set. The first two sets of examples are the incorrect predictions that are closest to 0.5; one for the training set and one for the test set. The other two sets of examples are the most extreme incorrect classifications. They have more extreme probabilities than would be justified by the examples.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.