Artificial
Intelligence 3E
foundations of computational agents
19.1 Deploying AI
During deployment, when AI is used in an application, the data comes from the world, and rather than using a test set to evaluate predictions, actions are carried out in the world. Figure 19.1 gives a decision tree to help choose which AI technologies to use.
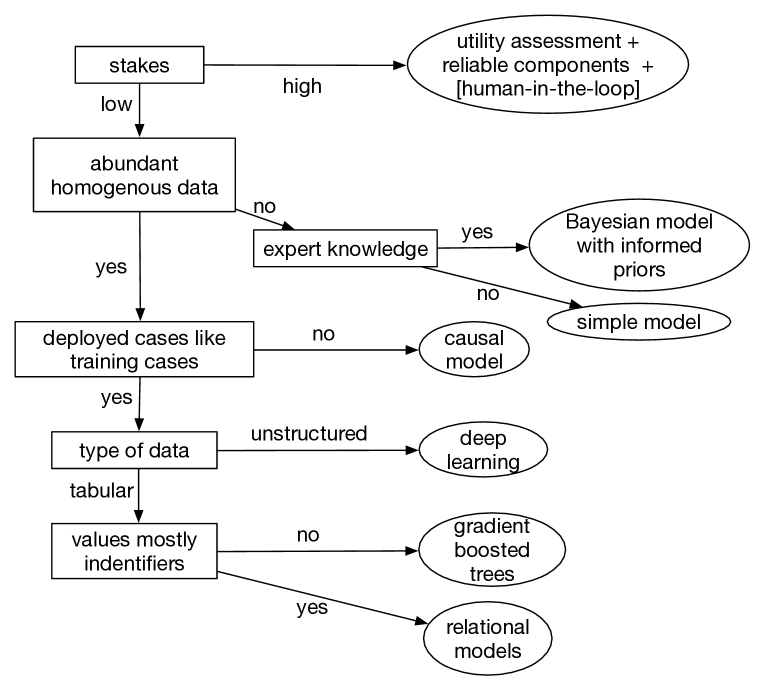
The conditions in this tree are:
-
•
At the top level is the choice of whether the stakes are high or low. The stakes are low when there are not severe consequences for errors, for example, in a game, for recommending what videos to watch, or suggesting a way to fold proteins when any resulting medicine will be fully tested. If a medical diagnostic agent is reminding doctors of possibilities they might have forgotten, it might have low stakes, even if it would have high stakes if it is relied on. In low-stakes cases, being better than the competition may be enough.
The stakes are high when people or the environment can be harmed or when a large amount of resources are spent for each decision. For decisions that are repeated, there are typically many possible outcomes that each have a low probability, but where the probability of one of them arising is very high. For example, in a self-driving car, there are many unusual things that could be on the road, each of which is unlikely, but with millions of cars, the probability that one of these will eventually be encountered by someone is very high. If the cost of errors is high, having a low error rate may mean an application is still high stakes.
-
•
When there is abundant homogenous data, for example from online images, text, high-throughput science experiments or when there is a simulator to generate data, as in a game, data-hungry machine learning tools can be used. Sometimes there is a lot of data, but it is heterogenous. For example, governments publish pollution data where there is, say, monthly or irregular testing of multiple pollutants at many locations, which become voluminous, even though there may be only tens or hundreds of data points for any particular location and pollutant. As another example, in medicine there are many rare diseases which have few (recorded) cases. Although each disease is rare, there are so many diseases that in a community it is common to find someone who has one of them. Because there are so many diseases, for most pairs of diseases, no one in the world has both, even though there are many people with multiple diseases.
-
•
When there is not a lot of data, often there is expert knowledge that can be applied. Experts have the advantage that they do more than learning from examples; they can build on established theories they learned in school or from reading books, and can bring in diverse knowledge.
-
•
Many machine learning algorithms assume that deployed cases are like training cases: the data used in deployment is from the same distribution as the training data. That assumption needs to be verified, and is often not appropriate. In real-world domains, as opposed to games, the future is typically not like the past, for example due to technology advances or global warming. You might not want the future to be like the past.
-
•
There are a number of types of data that arise. Some methods are used for unstructured and perceptual data, such as text, speech, images, video, and protein sequences, where there are no readily available features. Tabular data sometimes has values, such as categories, Booleans, and numbers, that can be used to form features. Sometimes in tabular data the values are mostly identifiers, such as student numbers, product ids, or transaction numbers, which contain no information in themselves about what they refer to.
When the stakes are low, there is abundant homogenous data and the deployed cases are expected to be like the training cases, pure machine learning can be used. Deep learning has proved to be the choice for unstructured and perceptual data where there are not pre-defined features, such as images, speech, text, and protein sequences. For tabular data where the values in the tables can be used to construct features, gradient-boosted trees, which use linear functions of conjunctions of propositions about these values, work well. Relational models are designed for tabular data with identifiers.
If the assumption that deployment is like training is inappropriate, a causal model) can be built that takes into account possible changes or missing data. Observational data alone is provably not sufficient to predict the effect of actions, such as in Simpson’s paradox. The conditional probabilities of a causal model can be learned using the methods of Chapters 7 or 8, or the whole model can be learned, taking into account the causality.
If there is not much data, but there is expert knowledge, building a causal model with informed priors (e.g., using a Dirichlet distribution) is a way to combine expertise and data in a way that smoothly interpolates between the case with no data, and when the data is overwhelming. If there is little data and no expertise, a simple model such as a decision tree or a linear model is typically the best that can be done, where the simplicity depends on the amount of data.
When the stakes are high, a complex cost–benefit analysis is appropriate, based on the utility of all stakeholders who might be affected by the decision. When considerable resources are required for the actions, or when poor outcomes can arise, decisions need to be explained. The system needs to be able to be debugged when errors arise. High-stakes cases typically use a combination of techniques, where each component is well tested and reliable.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.