Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
14.3 Probabilistic Relational Models
The belief network probability models of Chapter 6 were defined in terms of features. Many domains are best modeled in terms of individuals and relations. Agents must often build probabilistic models before they know what individuals are in the domain and, therefore, before they know what random variables exist. When the probabilities are being learned, the probabilities often do not depend on the individuals. Although it is possible to learn about an individual, an agent must also learn general knowledge that it can apply when it finds out about a new individual.
Consider the case of diagnosing two-digit addition of the form
x1 x0 + y1 y0 z2 z1 z0
The student is given the values for the x's and the y's and provides values for the z's.
Students' answers depend on whether they know basic addition and whether they know how to carry.
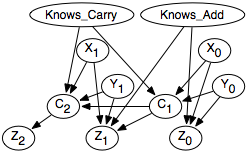
A belief network for this example is shown in Figure 14.2. The carry into digit i, given by the variable Ci, depends on the x-value, the y-value, and the carry for the previous digit, and on whether the student knows how to carry. The z-value for digit i, given by the variable Zi, depends on the x-value, the y-value, and the carry for digit i, in addition to whether the student knows basic addition.
By observing the value of the x's and the y's in the problem and the value of z's given by the student, the posterior probability that the student knows addition and knows how to carry can be inferred. One feature of the belief network model is that it allows students to make random errors; even though they know arithmetic, they can still get the wrong answer.
The problem with this representation is that it is inflexible. A flexible representation would allow for the addition of multiple digits, multiple problems, multiple students, and multiple times. Multiple digits require the replication of the network for the digits. Multiple times allow for modeling how students' knowledge and their answers change over time, even if the problems do not change over time.
If the conditional probabilities were stored as tables, the size of these tables would be enormous. For example, if the Xi, Yi, and Zi variables each have a domain size of 11 (the digits 0 to 9 or the blank), and the Ci and Knows_Add variables are binary, a tabular representation of
P(Z1|X1,Y1,C1,Knows_Add)
would have a size greater than 4,000. There is much more structure in the conditional probability than is expressed in the tabular representation. The representation that follows allows for both relational probabilistic models and compact descriptions of conditional probabilities.
A probabilistic relational model (PRM) or a relational probability model is a model in which the probabilities are specified on the relations, independently of the actual individuals. Different individuals share the probability parameters.
A parametrized random variable is either a logical atom or a term. That is, it is of the form p(t1,...,tn), where each ti is a logical variable or a constant. The parametrized random variable is said to be parametrized by the logical variables that appear in it. A ground instance of a parametrized random variable is obtained by substituting constants for the logical variables in the parametrized random variable. The ground instances of a parametrized random variable correspond to random variables. The random variables are Boolean if p is a predicate symbol. If p is a function symbol, the domain of the random variables is the range of p.
We use the convention that logical variables are in upper case. Random variables correspond to ground atoms and ground terms, so, for this section, these are written in lower case.
There is a variable for each student S and time T that represents whether S knows how to add properly at time T. The parametrized random variable knows_add(S,T) represents whether student S knows addition at time T. The random variable knows_add(fred,mar23) is true if Fred knows addition on March 23. Similarly, there is a parametrized random variable knows_carry(S,T).
There is a different z-value and a different carry for each digit, problem, student, and time. These values are represented by the parametrized random variables z(D,P,S,T) and carry(D,P,S,T). So, z(1,prob17,fred,mar23) is a random variable representing the answer Fred gave on March 23 for digit 1 of problem 17. Function z has range {0,...,9,blank}, so the random variables all have this set as their domain.
A plate model consists of
- a directed graph in which the nodes are parameterized random variables,
- a population of individuals for each logical variable, and
- a conditional probability of each node given its parents.
A plate model means its grounding - the belief network in which nodes are all ground instances of the parametrized random variables (each logical variable replaced by an individual in its population). The conditional probabilities of the belief network are the corresponding instances of the plate model.
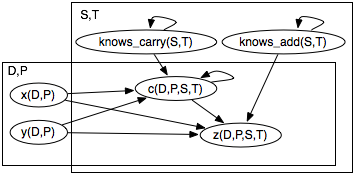
The plate representation denotes the same independence as a belief network; each node is independent of its non-descendants given its parents. In this case, the diagram describes its grounding. Thus, for particular values d∈dom(D), p∈dom(P), s∈dom(S), and t∈dom(T), z(d,p,s,t) is a random variable, with parents x(d,p), y(d,p), c(d,p,s,t) and knows_add(s,t). There is a loop in the plate model on the c(D,P,S,T) parametrized random variable because the carry for one digit depends on the carry for the previous digit for the same problem, student, and time. Similarly, whether students know how to carry at some time depends on whether they knew how to carry at the previous time. However, the conditional probability tables are such that the ground network is acyclic.
There is a conditional probability of each parametrized random variable, given its parents. This conditional probability is shared among its ground instances.
Unfortunately, the plate representation is not adequate when the dependency occurs among different instances of the same relation. In the preceding example, c(D,P,S,T) depends, in part, on c(D-1,P,S,T), that is, on the carry from the previous digit (and there is some other case for the first digit). A more complex example is to determine the probability that two authors are collaborators, which depends on whether they have written a paper in common. To represent such examples, it is useful to be able to specify how the logical variables interact, as is done in logic programs.
One representation that combines the ideas of belief networks, plates, and logic programs is the independent choice logic (ICL). The ICL consists of a set of independent choices, a logic program that gives the consequences of the choices, and probability distributions over the choices. In more detail, the ICL is defined as follows:
An alternative is a set of atoms all sharing the same logical variables. A choice space is a set of alternatives such that none of the atoms in the alternatives unify with each other. An ICL theory contains
- a choice space C. Let C' be the set of ground instances of the alternatives. Thus, C' is a set of sets of ground atoms.
- an acyclic logic program (that can include negation as failure), in which the head of the clauses doesn't unify with an element of an alternative in the choice space.
- a probability distribution over each alternative.
The atoms in the logic program and the choice space can contain constants, variables, and function symbols.
A selector function selects a single element from each alternative in C'. There exists a possible world for each selector function. The logic program specifies what is true in each possible world. Atom g is true in a possible world if it follows from the atoms selected by the selector function added to the logic program. The probability of proposition g is given by a measure over sets of possible worlds, where the atoms in different ground instances of the alternatives are probabilistically independent. The instances of an alternative share the same probabilities, and the probabilities of different instances are multiplied.
The acyclicity of the logic program means that only a finite number of alternatives exist with atoms involved in proofs of any ground g. So, although there may be infinitely many possible worlds, for any g, the probability measure can be defined on the sets of possible worlds that are describable in terms of a finite number of alternatives. A description of these worlds can be found by making the atoms in the alternatives assumable, with different atoms in the same alternative inconsistent, and by using abduction to find descriptions of the sets of worlds in which g is true.
An ICL theory can be seen as a causal model in which the causal mechanism is specified as a logic program and the background variables, corresponding to the alternatives, have independent probability distributions over them. It may seem that this logic, with only unconditionally independent atoms and a deterministic logic program, is too weak to represent the sort of knowledge required. However, even without logical variables, the independent choice logic can represent anything that can be represented in a belief network.
Fire and tampering have no parents, so they can be represented directly as alternatives:
{tampering,notampering}.
The probability distribution over the first alternative is P(fire)=0.01, P(nofire)=0.99. Similarly, P(tampering)=0.02, P(notampering)=0.89.
The dependence of Smoke on Fire can be represented using two alternatives:
{smokeWhenNoFire,nosmokeWhenNoFire},
with P(smokeWhenFire)=0.9 and P(smokeWhenNoFire)=0.01. Two rules can be used to specify when there is smoke:
smoke ←∼fire ∧smokeWhenNoFire.
To represent how Alarm depends on Fire and Tampering, there are four alternatives:
{alarmWhenNoTamperingFire,noalarmWhenNoTamperingFire},
{alarmWhenTamperingNoFire,noalarmWhenTamperingNoFire},
{alarmWhenNoTamperingNoFire,noalarmWhenNoTamperingNoFire},
where P(alarmWhenTamperingFire)=0.5, P(alarmWhenNoTamperingFire)=0.99, and similarly for the other atoms using the probabilities from Example 6.10. There are also rules specifying when alarm is true, depending on tampering and fire:
alarm ←∼tampering ∧fire ∧alarmWhenNoTamperingFire.
alarm ←tampering ∧∼fire ∧alarmWhenTamperingNoFire.
alarm ←∼tampering ∧∼fire ∧alarmWhenNoTamperingNoFire.
Other random variables are represented analogously, using the same number of alternatives as there are assignments of values to the parents of a node.
An ICL representation of a conditional probability can be seen as a rule form of a decision tree with probabilities at the leaves. There is a rule and an alternative for each branch. Non-binary alternatives are useful when non-binary variables are involved.
The independent choice logic may not seem very intuitive for representing standard belief networks, but it can make complicated relational models much simpler, as in the following example.
There are three cases for the value of z(D,P,S,T). The first is when the student knows addition at this time, and the student did not make a mistake. In this case, they get the correct answer:
x(D,P,Vx) ∧
y(D,P,Vy) ∧
carry(D,P,S,T,Vc) ∧
knowsAddition(S,T) ∧
∼mistake(D,P,S,T) ∧
V is (Vx+Vy+Vc) div 10.
Here we write the atom z(D,P,S,T,V) to mean that the parametrized random variable z(D,P,S,T) has value V. This is a standard logical rule and has the same meaning as a definite clause.
There is an alternative for whether or not the student happened to make a mistake in this instance:
where the probability of mistake(D,P,S,T) is 0.05, assuming students make an error in 5% of the cases even when they know how to do arithmetic.
The second case is when the student knows addition at this time but makes a mistake. In this case, we assume that the students are equally likely to pick each of the digits:
knowsAddition(S,T) ∧
mistake(D,P,S,T) ∧
selectDig(D,P,S,T,V).
There is an alternative that specifies which digit the student chose:
Suppose that, for each v, the probability of selectDig(D,P,S,T,v) is 0.1.
The final case is when the student does not know addition. In this case, the student selects a digit at random:
∼knowsAddition(S,T) ∧
selectDig(D,P,S,T)=V.
These three rules cover all of the rules for z; it is much simpler than the table of size greater than 4,000 that was required for the tabular representation and it also allows for arbitrary digits, problems, students, and times. Different digits and problems give different values for x(D,P), and different students and times have different values for whether they know addition.
The rules for carry are similar. The main difference is that the carry in the body of the rule depends on the previous digit.
Whether a student knows addition at any time depends on whether they know addition at the previous time. Presumably, the student's knowledge also depends on what actions occur (what the student and the teacher do). Because the ICL allows standard logic programs (with "noise"), either of the representations for modeling change introduced at the start of this chapter can be used.
AILog, as used in the previous chapters, also implements ICL.
Relational, Identity, and Existence Uncertainty
The models presented in Section 14.3 are concerned with relational uncertainty; uncertainty about whether a relation is true of some individuals. For example, we could have a probabilistic model of likes(X,Y) for the case where X≠Y, which models when different people like each other. This could depend on external characteristic of X and Y. We could also have a probabilistic model for likes(X,X), which models whether someone likes themselves. This could depend on internal characteristics of themselves. Such models would be useful for a tutoring system to determine whether two people should work together.
Given individuals sam and chris, we can use the first of these models for likes(sam,chris) only if we know that Sam and Chris are different people. The problem of identity uncertainty concerns uncertainty of whether, or not, two terms denote the same individual. This is a problem for medical systems, where it is important to determine whether the person who is interacting with the system now is the same person as one who visited yesterday. This problem is particularly difficult if the patient is non-communicative or wants to deceive the system, for example to get drugs. In the medical community, this is the problem of record linkage, as the problem is to determine which medical records are for the same people. In all of the above cases, the individuals are known to exist; to give names to Chris and Sam presupposes that they exist. Given a description, the problem of determining if there exists an individual that fits the description is the problem of existence uncertainty. Existence uncertainty is problematic because there may be no individuals who fit the description or there may be multiple individuals. We cannot give properties to non-existent individuals, because individuals that do not exist do not have properties. If we want to give a name to an individual that exists, we need to be concerned about which individual we are referring to if there are multiple individuals that exist. One particular case of existence uncertainty is number uncertainty, about the number of individuals that exist. For example, a purchasing agent may be uncertain about the number of people who would be interested in a package tour, and whether to offer the tour depends on the number of people who may be interested.
Reasoning about existence uncertainty can be very tricky if there are complex roles involved, and the problem is to determine if there are individuals to fill the roles. Consider a purchasing agent who must find an apartment for Sam and her son Chris. Whether Sam wants an apartment probabilistically depends, in part, on the size of her room and the color of Chris' room. However, individual apartments do not come labeled with Sam's room and Chris' room, and there may not exist a room for each of them. Given a model of an apartment Sam would want, it isn't obvious how to even condition on the observations.
