Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
7.3.3 Bayesian Classifiers
A Bayesian classifier is based on the idea that the role of a (natural) class is to predict the values of features for members of that class. Examples are grouped in classes because they have common values for the features. Such classes are often called natural kinds. In this section, the target feature corresponds to a discrete class, which is not necessarily binary.
The idea behind a Bayesian classifier is that, if an agent knows the class, it can predict the values of the other features. If it does not know the class, Bayes' rule can be used to predict the class given (some of) the feature values. In a Bayesian classifier, the learning agent builds a probabilistic model of the features and uses that model to predict the classification of a new example.
A latent variable is a probabilistic variable that is not observed. A Bayesian classifier is a probabilistic model where the classification is a latent variable that is probabilistically related to the observed variables. Classification then become inference in the probabilistic model.
The simplest case is the naive Bayesian classifier, which makes the independence assumption that the input features are conditionally independent of each other given the classification. The independence of the naive Bayesian classifier is embodied in a particular belief network where the features are the nodes, the target variable (the classification) has no parents, and the classification is the only parent of each input feature. This belief network requires the probability distributions P(Y) for the target feature Y and P(Xi|Y) for each input feature Xi. For each example, the prediction can be computed by conditioning on observed values for the input features and by querying the classification.
Given an example with inputs X1=v1,...,Xk=vk, Bayes' rule is used to compute the posterior probability distribution of the example's classification, Y:
P(Y | X1=v1,...,Xk=vk) = (P(X1=v1,...,Xk=vk| Y) ×P(Y))/(P(X1=v1,...,Xk=vk)) = (P(X1=v1|Y)×···×P(Xk=vk| Y)×P(Y))/( ∑Y P(X1=v1|Y)×···×P(Xk=vk| Y) ×P(Y))
where the denominator is a normalizing constant to ensure the probabilities sum to 1. The denominator does not depend on the class and, therefore, it is not needed to determine the most likely class.
To learn a classifier, the distributions of P(Y) and P(Xi|Y) for each input feature can be learned from the data, as described in Section 7.2.3. The simplest case is to use the empirical frequency in the training data as the probability (i.e., use the proportion in the training data as the probability). However, as shown below, this approach is often not a good idea when this results in zero probabilities.
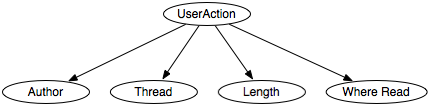
Suppose the agent uses the empirical frequencies as the probabilities for this example. The probabilities that can be derived from these data are
P(User Action=reads) = (9)/(18) = 0.5 P(Author=known|User Action=reads) = (2)/(3) P(Author=known|User Action=skips) = (2)/(3) P(Thread=new|User Action=reads) = (7)/(9) P(Thread=new|User Action=skips) = (1)/(3) P(Length=long|User Action=reads) = 0 P(Length=long|User Action=skips) = (7)/(9) P(Where Read=home|User Action=reads) = (4)/(9) P(Where Read=home|User Action=skips) = (4)/(9) .
Based on these probabilities, the features Author and Where Read have no predictive power because knowing either does not change the probability that the user will read the article. The rest of this example ignores these features.
To classify a new case where the author is unknown, the thread is a follow-up, the length is short, and it is read at home,
P(User Action=reads | Thread=follow Up ∧Length=short) = P(follow Up|reads) ×P(short| reads) ×P(reads) ×c = (2)/(9)×1 ×(1)/(2) ×c = (1)/(9)×c
P(User Action=skips | Thread=follow Up ∧Length=short) = P(follow Up|skips) ×P(short| skips) ×P(skips)×c = (2)/(3)×(2)/(9) ×(1)/(2) ×c = (2)/(27)×c
where c is a normalizing constant that ensures these add up to 1. Thus, c must be (27)/(5), so
P(User Action=reads | Thread=follow Up ∧Length=short)=0.6 .
This prediction does not work well on example e11, which the agent skips, even though it is a followUp and is short. The naive Bayesian classifier summarizes the data into a few parameters. It predicts the article will be read because being short is a stronger indicator that the article will be read than being a follow-up is an indicator that the article will be skipped.
A new case where the length is long has P(length=long|User Action=reads) = 0. Thus, the posterior probability that the User Action=reads is zero, no matter what the values of the other features are.
The use of zero probabilities can imply some unexpected behavior. First, some features become predictive: knowing just one feature value can rule out a category. If we allow zero probabilities, it is possible that some combinations of observations are impossible. See Exercise 7.13. This is a problem not necessarily with using a Bayesian classifier but rather in using empirical frequencies as probabilities. The alternative to using the empirical frequencies is to incorporate pseudocounts. A designer of the learner should carefully choose pseudocounts, as shown in the following example.
The learner must learn P(H). To do this, it starts with a pseudocount for each hi. Pages that are a priori more likely can have a higher pseudocount. If the designer did not have any prior belief about which pages were more likely, the agent could use the same pseudocount for each page. To think about what count to use, the designer should consider how much more the agent would believe a page is the correct page after it has seen the page once; see Section 7.2.3. It is possible to learn this pseudocount, if the designer has built another help system, by optimizing the pseudocount over the training data for that help system [or by using what is called a hierarchical Bayesian model]. Given the pseudocounts and some data, P(hi) can be computed by dividing the count (the empirical count plus the pseudocount) associated with hi by the sum of the counts for all of the pages.
For each word wj and for each help page hi, the helping agent requires two counts - the number of times wj was used when hi was the appropriate page (call this cij+) and the the number of times wj was not used when hi was the appropriate page (call this cij-). Neither of these counts should be zero. We expect cij- to be bigger on average than cij+, because we expect the average query to use a small portion of the total number of words. We may want to use different counts for those words that appear in the help page hi than for those words that do not appear in hi, so that the system starts with sensible behavior.
Every time a user claims they have found the help page they are interested in, the counts for that page and the conditional counts for all of the words can be updated. That is, if the user says that hi is the correct page, the count associated with hi can be incremented, cij+ is incremented for each word wj used in the query, and cij- is incremented for each wj not in the query.
This model does not use information about the wrong page. If the user claims that a page is not the correct page, this information is not used until the correct page is found.
The biggest challenge in building such a help system is not in the learning but in acquiring useful data. In particular, users may not know whether they have found the page they were looking for. Thus, users may not know when to stop and provide the feedback from which the system learns. Some users may never be satisfied with a page. Indeed, there may not exist a page they are satisfied with, but that information never gets fed back the learner. Alternatively, some users may indicate they have found the page they were looking for, even though there may be another page that was more appropriate. In the latter case, the correct page may have its count reduced so that it is never discovered.
Although there are some cases where the naive Bayesian classifier does not produce good results, it is extremely simple, it is easy to implement, and often it works very well. It is a good method to try for a new problem.
In general, the naive Bayesian classifier works well when the independence assumption is appropriate, that is, when the class is a good predictor of the other features and the other features are independent given the class. This may be appropriate for natural kinds, where the classes have evolved because they are useful in distinguishing the objects that humans want to distinguish. Natural kinds are often associated with nouns, such as the class of dogs or the class of chairs.
