Artificial
Intelligence 3E
foundations of computational agents
6.2 Forward Planning
A deterministic plan is a sequence of actions to achieve a goal from a given starting state. A deterministic planner produces a plan given an initial world description, a specification of the actions available to the agent, and a goal description.
A forward planner treats the planning problem as a path planning problem in the state-space graph, which can be explored. In a state-space graph, nodes are states and arcs correspond to actions from one state to another. The arcs coming out of state correspond to all of the legal actions that can be carried out in that state. That is, for each state, there is an arc for each action whose precondition holds in state . A plan is a path from the initial state to a state that satisfies the achievement goal.
A forward planner searches the state-space graph from the initial state looking for a state that satisfies a goal description. It can use any of the search strategies described in Chapter 3.
The search graph is defined as follows:
-
•
The nodes are states of the world, where a state is a total assignment of a value to each feature.
-
•
The arcs correspond to actions. In particular, an arc from node to , labeled with action , means is possible in and carrying out in state results in state .
-
•
The start node is the initial state.
-
•
The goal condition for the search, , is true if state satisfies the achievement goal.
-
•
A path corresponds to a plan that achieves the goal.
Example 6.9.
For the running example, a state can be represented as a quintuple
of values for the respective variables.
Figure 6.2 shows part of the search space (without showing the loops) starting from the state where Rob is at the coffee shop, Rob does not have coffee, Sam wants coffee, there is mail waiting, and Rob does not have mail. The search space is the same irrespective of the goal state.
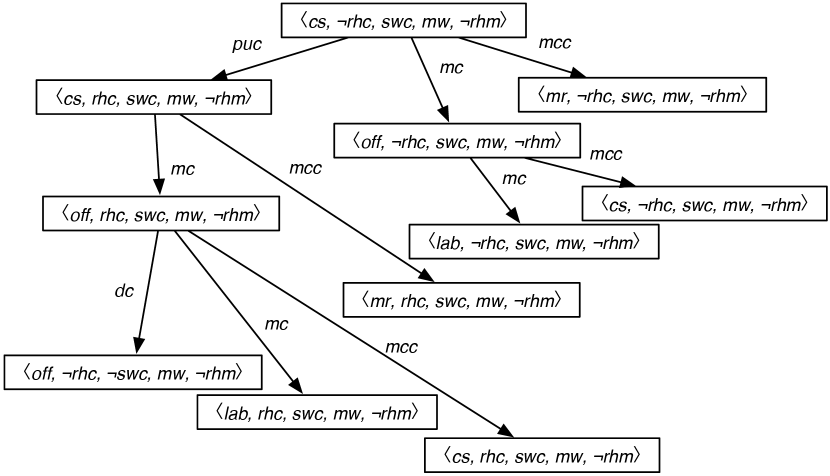
Using a forward planner is not the same as making an explicit state-based representation of the actions, because the relevant parts of the graph are created dynamically from the representations of the actions.
A complete search strategy, such as with multiple-path pruning or depth-first branch and bound, is guaranteed to find a solution. The complexity of the search space is defined by the forward branching factor of the graph. The branching factor is the set of all possible actions at any state, which may be quite large. For the simple robot delivery domain, the branching factor is three for the initial situation and is up to four for other situations. This complexity may be reduced by finding good heuristics, so that not all of the space is searched if there is a solution.
For a forward planner, a heuristic function for a state is an estimate of the cost of solving the goal from the state.
Example 6.10.
For the delivery robot plan, if all actions have a cost of 1, a possible admissible heuristic function given a particular goal, is the maximum of:
-
•
the distance from the robot location in the state to the goal location, if there is one
-
•
the distance from the robot’s location in state to the coffee shop plus three (because the robot has to, at least, get to the coffee shop, pick up the coffee and get to the office to deliver the coffee) if the goal includes and state has and .
A state can be represented as either
-
(a)
a complete world description, in terms of an assignment of a value to each primitive proposition, or
-
(b)
a path from an initial state; that is, by the sequence of actions that were used to reach that state from the initial state. In this case, what holds in a state is computed from the axioms that specify the effects of actions.
Choice (a) involves computing a whole new world description for each world created, whereas (b) involves computing what holds in a state as needed. Alternative (b) may save on space (particularly if there is a complex world description) and may allow faster creation of a new node, however it is slower to determine what actually holds in any given world. Each representation requires a way to determine whether two states are the same if cycle pruning or multiple-path pruning are used.
State-space searching has been presented as a forward search method, but it is also possible to search backward from the set of states that satisfy the goal. Typically, the goal does not fully specify a state, so there may be many goal states that satisfy the goal. If there are multiple states, create a node, , that has, as neighbors, all of the goal states, and use this as the start node for backward search. Once is expanded, the frontier has as many elements as there are goal states, which can be very large, making backward search in the state space impractical for non-trivial domains.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.