Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
9.5.5 Partially Observable Decision Processes
Dimensions: flat, states, infinite horizon, partially observable, stochastic, utility, non-learning, single agent, offline, perfect rationality
A partially observable Markov decision process (POMDP) is a combination of an MDP and a hidden Markov model. Instead of the state being observable, there are partial and/or noisy observations of the state that the agent gets to observe before it has to act.
A POMDP consists of
-
•
, a set of states of the world
-
•
, a set of actions
-
•
, a set of possible observations
-
•
, which gives the probability distribution of the starting state
-
•
, which specifies the dynamics – the probability of getting to state by doing action from state
-
•
, which gives the expected reward of starting in state , doing action , and transitioning to state , and
-
•
, which gives the probability of observing given the state is .
A finite part of a POMDP can be depicted using the decision diagram as in Figure 9.22.
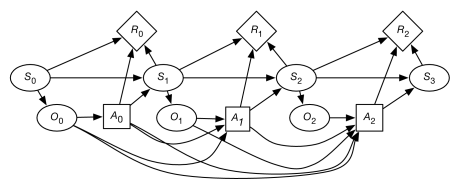
There are three main ways to approach the problem of computing the optimal policy for a POMDP:
-
•
Solve the associated dynamic decision network using variable elimination for decision networks (Figure 9.13, extended to include discounted rewards). The policy created is a function of the history of the agent. The problem with this approach is that the history is unbounded, and the size of a policy is exponential in the length of the history. This only works when the history is short or is deliberately cut short.
-
•
Make the policy a function of the belief state – a probability distribution over the states. Maintaining the belief state is the problem of filtering. The problem with this approach is that, with states, the set of belief states is an -dimensional real space. However, because the value of a sequence of actions only depends on the states, the expected value is a linear function of the values of the states. Because plans can be conditional on observations, and we only consider optimal actions for any belief state, the optimal policy for any finite look-ahead, is piecewise linear and convex.
-
•
Search over the space of controllers for the best controller. Thus, the agent searches over what to remember and what to do based on its belief state and observations. Note that the first two proposals are instances of this approach: the agent remembers all of its history or the agent has a belief state that is a probability distribution over possible states. In general, the agent may want to remember some parts of its history but have probabilities over some other features. Because it is unconstrained over what to remember, the search space is enormous.