Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
9.5.4 Dynamic Decision Networks
Dimensions: flat, features, infinite horizon, fully observable, stochastic, utility, non-learning, single agent, offline, perfect rationality
A Markov decision process is a state-based representation. Just as in classical planning, where reasoning in terms of features can allow for more straightforward representations and more efficient algorithms, planning under uncertainty can also take advantage of reasoning in term of features. This forms the basis for decision-theoretic planning.
A dynamic decision network (DDN) can be seen in a number of different ways:
-
•
a factored representation of MDPs, where the states are described in terms of features
-
•
an extension of decision networks to allow repeated structure for indefinite or infinite horizon problems
-
•
an extension of dynamic belief networks to include actions and rewards
-
•
an extension of the feature-based representation of actions or the CSP representation of planning to allow for rewards and for uncertainty in the effect of actions.
A dynamic decision network consists of
-
•
a set of state features
-
•
a set of possible actions
-
•
a two-stage decision network with chance nodes and for each feature (for the features at time 0 and time 1, respectively) and decision node , such that
-
–
the domain of is the set of all actions
-
–
the parents of are the set of time 0 features (these arcs are often not shown explicitly)
-
–
the parents of time 0 features do not include or time 1 features, but can include other time 0 features as long as the resulting network is acyclic
-
–
the parents of time 1 features can contain and other time 0 or time 1 features as long as the graph is acyclic
-
–
there are probability distributions for and for each feature
-
–
the reward function depends on any subset of the action and the features at times 0 or 1.
-
–
As in a dynamic belief network, a dynamic decision network can be unfolded into a decision network by replicating the features and the action for each subsequent time. For a time horizon of , there is a variable for each feature and for each time for . For a time horizon of , there is a variable for each time for . The horizon, , can be unbounded, which allows us to model processes that do not halt.
Thus, if there are features for a time horizon of there are chance nodes (each representing a random variable) and decision nodes in the unfolded network.
The parents of are random variables (so that the agent can observe the state). Each depends on the action and the features at time and in the same way, with the same conditional probabilities, as depends the action and the features at time and . The variables modeled directly in the two-stage decision network.
Example 9.34.
Example 6.1 models a robot that can deliver coffee and mail in a simple environment with four locations. Consider representing a stochastic version of Example 6.1 as a dynamic decision network. We use the same features as in that example.
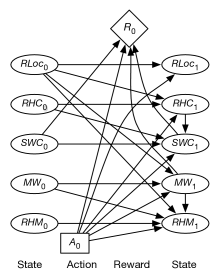
Feature models the robot’s location. The parents of variables are and .
Feature is true when the robot has coffee. The parents of are , , and ; whether the robot has coffee depends on whether it had coffee before, what action it performed, and its location. The probabilities can encode the possibilities that the robot does not succeed in picking up or delivering the coffee, that it drops the coffee, or that someone gives it coffee in some other state (which we may not want to say is impossible).
Variable is true when Sam wants coffee. The parents of include , , , and . You would not expect and to be independent because they both depend on whether or not the coffee was successfully delivered. This could be modeled by having one be a parent of the other.
The two-stage belief network representing how the state variables at time 1 depend on the action and the other state variables is shown in Figure 9.19. This figure also shows the reward as a function of the action, whether Sam stopped wanting coffee, and whether there is mail waiting.
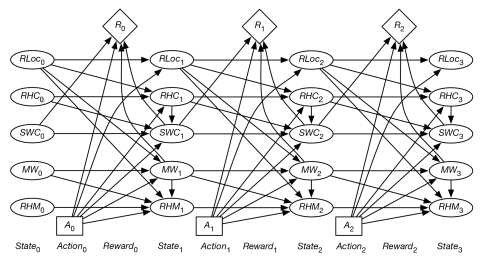
Figure 9.20 shows the unfolded decision network for a horizon of 3.
Example 9.35.
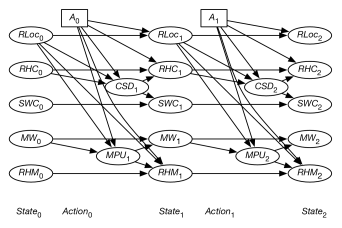
An alternate way to model the dependence between and is to introduce a new variable, , which represents whether coffee was successfully delivered at time . This variable is a parent of both and . Whether Sam wants coffee is a function of whether Sam wanted coffee before and whether coffee was successfully delivered. Whether the robot has coffee depends on the action and the location, to model the robot picking up coffee. Similarly, the dependence between and can be modeled by introducing a variable , which represents whether the mail was successfully picked up. The resulting DDN unfolded to a horizon of 2, but omitting the reward, is shown in Figure 9.21.
If the reward comes only at the end, variable elimination for decision networks, shown in Figure 9.13, can be applied directly. Variable elimination for decision networks corresponds to value iteration. Note that in fully observable decision networks variable elimination does not require the no-forgetting condition. Once the agent knows the state, all previous decisions are irrelevant. If rewards are accrued at each time step, the algorithm must be augmented to allow for the addition (and discounting) of rewards. See Exercise 18.