Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
8.5.2 Hidden Markov Models
A hidden Markov model (HMM) is an augmentation of a Markov chain to include observations. A hidden Markov model includes the state transition of the Markov chain, and adds to it observations at each time that depend on the state at the time. These observations can be partial in that different states map to the same observation and noisy in that the same state stochastically maps to different observations at different times.
The assumptions behind an HMM are:
-
•
The state at time only directly depends on the state at time for , as in the Markov chain.
-
•
The observation at time only directly depends on the state at time .
The observations are modeled using the variable for each time whose domain is the set of possible observations. The belief network representation of an HMM is depicted in Figure 8.12. Although the belief network is shown for five stages, it extends indefinitely.
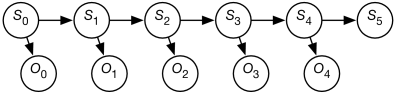
A stationary HMM includes the following probability distributions:
-
•
specifies initial conditions
-
•
specifies the dynamics
-
•
specifies the sensor model.
Example 8.29.
Suppose you want to keep track of an animal in a triangular enclosure using sound. You have three microphones that provide unreliable (noisy) binary information at each time step. The animal is either near one of the 3 vertices of the triangle or close to the middle of the triangle. The state has domain where means the animal is in the middle and means the animal is in corner .
The dynamics of the world is a model of how the state at one time depends on the previous time. If the animal is in a corner it stays in the same corner with probability 0.8, goes to the middle with probability 0.1 or goes to one of the other corners with probability 0.05 each. If it is in the middle, it stays in the middle with probability 0.7, otherwise it moves to one of the corners, each with probability 0.1.
The sensor model specifies the probability of detection by each microphone given the state. If the animal is in a corner, it will be detected by the microphone at that corner with probability 0.6, and will be independently detected by each of the other microphones with a probability of 0.1. If the animal is in the middle, it will be detected by each microphone with a probability of 0.4.
Initially the animal is in one of the four states, with equal probability.
There are a number of tasks that are common for HMMs.
The problem of filtering or belief-state monitoring is to determine the current state based on the current and previous observations, namely to determine
All state and observation variables after are irrelevant because they are not observed and can be ignored when this conditional distribution is computed.
Example 8.30.
Consider filtering for Example 8.29.
The following table gives the observations for each time, and the resulting state distribution. There are no observations at time 0.
| Observation | Posterior State Distribution | ||||||
| Time | Mic#1 | Mic#2 | Mic#3 | ||||
| 0 | – | – | – | 0.25 | 0.25 | 0.25 | 0.25 |
| 1 | 0 | 1 | 1 | 0.46 | 0.019 | 0.26 | 0.26 |
| 2 | 1 | 0 | 1 | 0.64 | 0.084 | 0.019 | 0.26 |
Thus, even with only two time steps of noisy observations from initial ignorance, it is very sure that the animal is not at corner 1 or corner 2. It is most likely that the animal is in the middle.
Note that the posterior at any time only depended on the observations up to that time. Filtering does not take into account future observations that provide more information about the initial state.
The problem of smoothing is to determine a state based on past and future observations. Suppose an agent has observed up to time and wants to determine the state at time for ; the smoothing problem is to determine
All of the variables and for can be ignored.
Localization
Suppose a robot wants to determine its location based on its history of actions and its sensor readings. This is the problem of localization.
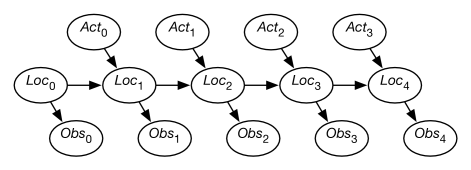
Figure 8.13 shows a belief-network representation of the localization problem. There is a variable for each time , which represents the robot’s location at time . There is a variable for each time , which represents the robot’s observation made at time . For each time , there is a variable that represents the robot’s action at time . In this section, assume that the robot’s actions are observed. (The case in which the robot chooses its actions is discussed in Chapter 9).
This model assumes the following dynamics: At time , the robot is at location , it observes , then it acts, it observes its action , and time progresses to time , where it is at location . Its observation at time only depends on the state at time . The robot’s location at time depends on its location at time and its action at time . Its location at time is conditionally independent of previous locations, previous observations, and previous actions, given its location at time and its action at time .
The localization problem is to determine the robot’s location as a function of its observation history:
Example 8.31.
Consider the domain depicted in Figure 8.14.

There is a circular corridor, with 16 locations numbered 0 to 15. The robot is at one of these locations at each time. This is modeled with, for every time , a variable with domain .
-
•
There are doors at positions 2, 4, 7, and 11 and no doors at other locations.
-
•
The robot has a sensor that noisily senses whether or not it is in front of a door. This is modeled with a variable for each time , with domain . Assume the following conditional probabilities:
where is true when the robot is at states 2, 4, 7, or 11 at time , and is true when the robot is at the other states.
Thus, the observation is partial in that many states give the same observation and it is noisy in the following way: in 20% of the cases in which the robot is at a door, the sensor falsely gives a negative reading. In 10% of the cases where the robot is not at a door, the sensor records that there is a door.
-
•
The robot can, at each time, move left, move right, or stay still. Assume that the stay still action is deterministic, but the dynamics of the moving actions are stochastic. Just because the robot carries out the action does not mean that it actually goes one step to the right – it is possible that it stays still, goes two steps right, or even ends up at some arbitrary location (e.g., if someone picks up the robot and moves it). Assume the following dynamics, for each location :
All location arithmetic is modulo 16. The action works the same way but to the left.
The robot starts at an unknown location and must determine its location.
It may seem as though the domain is too ambiguous, the sensors are too noisy, and the dynamics is too stochastic to do anything. However, it is possible to compute the probability of the robot’s current location given its history of actions and observations.

Figure 8.15 gives the robot’s probability distribution over its locations, assuming it starts with no knowledge of where it is and experiences the following observations: observe door, go right, observe no door, go right, and then observe door. Location 4 is the most likely current location, with posterior probability of 0.42. That is, in terms of the network of Figure 8.13:
Location 7 is the second most likely current location, with posterior probability of 0.141. Locations 0, 1, 3, 8, 12, and 15 are the least likely current locations, with posterior probability of 0.011.
You can see how well this works for other sequences of observations by using the applet at the book website.
Example 8.32.
Let us augment Example 8.31 with another sensor. Suppose that, in addition to a door sensor, there is also a light sensor. The light sensor and the door sensor are conditionally independent given the state. Suppose the light sensor is not very informative; it only gives yes-or-no information about whether it detects any light, and this is very noisy, and depends on the location.
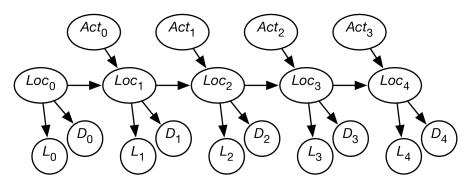
This is modeled in Figure 8.16 using the following variables:
-
•
is the robot’s location at time
-
•
is the robot’s action at time
-
•
is the door sensor value at time
-
•
is the light sensor value at time .
Conditioning on both and lets it combine information from the light sensor and the door sensor. This is an instance of sensor fusion. It is not necessary to define any new mechanisms for sensor fusion given the belief-network model; standard probabilistic inference combines the information from both sensors.