Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
7.4.3 Cross Validation
The problem with the previous methods is that they require a notion of simplicity to be known before the agent has seen any data. It would seem that an agent should be able to determine, from the data, how complicated a model needs to be. Such a method could be used when the learning agent has no prior information about the world.
The idea of cross validation is to use part of the training data as a surrogate for test data. In the simplest case, we split the training set into two: a set of examples to train with, and a validation set. The agent trains using the new training set. Prediction on the validation set is used to determine which model to use.
Consider a graph such as the one in Figure 7.14. The error on the training set gets smaller as the size of the tree grows. However, on the test set the error typically improves for a while and then starts to get worse. The idea of cross validation is to choose a parameter setting or a representation in which the error of the validation set is a minimum. The hypothesis is that this is where the error on the test set is also at a minimum.
The validation set that is used as part of training is not the same as the test set. The test set is used to evaluate how well the learning algorithm works as a whole. It is cheating to use the test set as part of learning. Remember that the aim is to predict examples that the agent has not seen. The test set acts as a surrogate for these unseen examples, and so it cannot be used for training or validation.
Typically, we want to train on as many examples as possible, because then we get better models. However, a bigger training set results in a smaller validation set, and a small validation set may fit well, or not fit well, just by luck.
The method of -fold cross validation allows us to reuse examples for both training and validation, but still use all of the data for training. It can be used to tune parameters that control the model complexity, or otherwise affect the model learned. It has the following steps:
-
•
Partition the training examples randomly into sets, of approximately equal size, called folds.
-
•
To evaluate a parameter setting, train times for that parameter setting, each time using one of the folds as the validation set and the remaining folds for training. Thus each fold is used as a validation set exactly once. The accuracy is evaluated using the validation set. For example, if , then 90% of the training examples are used for training and 10% of the examples for validation. It does this 10 times, so each example is used once in a validation set.
-
•
Optimize parameter settings based on the error on each example when it is used in the validation set.
-
•
Return the model with the selected parameter settings, trained on all of the data.
Example 7.19.
One of the possible parameters for the decision tree learner is the minimum number of examples that needs to be in the data set to split, so the stopping criterion for the decision tree learner of Figure 7.7 will be true if the number of examples is less than . If this threshold is too small, the decision tree learner will tend to overfit, and if it is too large it will tend not to generalize.
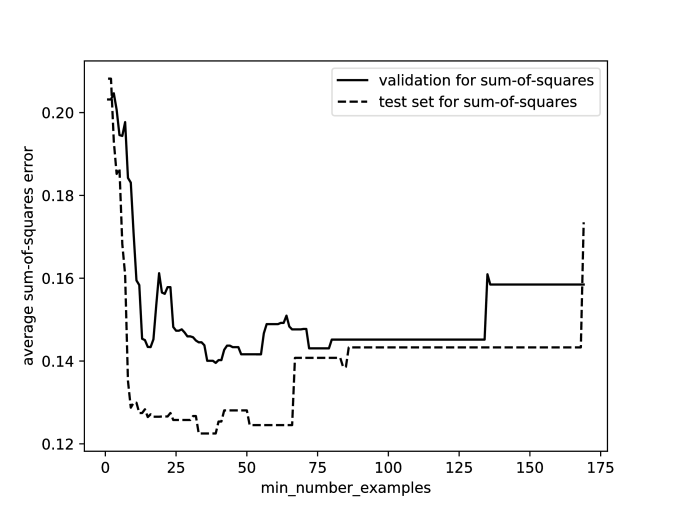
Figure 7.15 shows the validation error for 5-fold cross validation as a function of the parameter . For each point on the -axis, the decision tree was run 5 times, and the average sum-of-squares error was computed for the validation set. The error is at a minimum at 39, and so this is selected as the best value for this parameter. This plot also shows the error on the test set for trees with various settings for the minimum number of examples, and 39 is a reasonable parameter setting based on the test set.
At one extreme, when is the number of training examples, -fold cross validation becomes leave-one-out cross validation. With examples in the training set, it learns times; for each example , it uses the other examples as training set, and evaluates on . This is not practical if each training is done independently, because it increases the complexity by the number of training examples. However, if the model from one run can be adjusted quickly when one example is removed and another added, this can be very effective.