Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
7.3.1 Learning Decision Trees
A decision tree is a simple representation for classifying examples. Decision tree learning is one of the simplest useful techniques for supervised classification learning. For this section, assume there is a single discrete target feature called the classification. Each element of the domain of the classification is called a class.
A decision tree or a classification tree is a tree in which
-
•
each internal (non-leaf) node is labeled with a condition, a Boolean function of examples
-
•
each internal node has two children, one labeled with and the other with
-
•
each leaf of the tree is labeled with a point estimate on the class.
To classify an example, filter it down the tree, as follows. Each condition encountered in the tree is evaluated and the arc corresponding to the result is followed. When a leaf is reached, the classification corresponding to that leaf is returned. A decision tree corresponds to a nested if-then-else structure in a programming language.
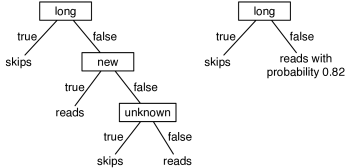
Example 7.7.
Figure 7.6 shows two possible decision trees for the examples of Figure 7.1. Each decision tree can be used to classify examples according to the user’s action. To classify a new example using the tree on the left, first determine the length. If it is long, predict . Otherwise, check the thread. If the thread is new, predict . Otherwise, check the author and predict only if the author is known. This decision tree can correctly classify all examples in Figure 7.1.
The tree corresponds to the program defining :
| define : | |
| if : return | |
| else if : return | |
| else if : return | |
| else: return |
The tree on the right makes probabilistic predictions when the length is not . In this case, it predicts with probability 0.82 and so with probability 0.18.
To use decision trees as a target representation, there are a number of questions that arise:
-
•
Given some training examples, what decision tree should be generated? Because a decision tree can represent any function of discrete input features, the bias that is necessary is incorporated into the preference of one decision tree over another. One proposal is to prefer the smallest tree that is consistent with the data, which could mean the tree with the least depth or the tree with the fewest nodes. Which decision trees are the best predictors of unseen data is an empirical question.
-
•
How should an agent go about building a decision tree? One way is to search the space of decision trees for the smallest decision tree that fits the data. Unfortunately, the space of decision trees is enormous (see Exercise 5). A practical solution is to carry out a greedy search on the space of decision trees, with the goal of minimizing the error. This is the idea behind the algorithm described below.
Searching for a Good Decision Tree
The algorithm of Figure 7.7 builds a decision tree from the top down as follows. The input to the algorithm is a set of input conditions (Boolean functions of examples that use only input features), a target feature, and a set of training examples. If the input features are Boolean, they can be used directly as the conditions.
A decision tree can be seen as a simple branching program, taking in an example and returning a prediction for that example, either
-
•
a prediction that ignores the input conditions (a leaf) or
-
•
of the form “if then else ” where and are decision trees; is the tree that is used when the condition is true of example , and is the tree used when is false.
The learning algorithm mirrors this recursive decomposition of a tree. The learner first tests whether a stopping criterion is true. If the stopping criterion is true, it determines a point estimate for , which is either a value for or a probability distribution over the values for . The function returns a value for that can be predicted for all examples , ignoring the input features. The algorithm returns a function that returns that point estimate for any example. This is a leaf of the tree.
If the stopping criterion is not true, the learner picks a condition to split on, it partitions the training examples into those examples with true and those examples with true (i.e., ). It recursively builds a subtree for these sets of examples. It then returns a function that, given an example, tests whether is true of the example, and then uses the prediction from the appropriate subtree.
Example 7.8.
Consider applying to the classification data of Figure 7.1. The initial call is
Suppose the stopping criterion is not true and the algorithm picks the condition to split on. It then calls
All of these examples agree on the user action; therefore, the algorithm returns the prediction . The second step of the recursive call is
Not all of the examples agree on the user action, so assuming the stopping criterion is false, the algorithm picks a condition to split on. Suppose it picks . Eventually, this recursive call returns the function on example in the case when is :
The final result is the function of Example 7.7.
The learning algorithm of Figure 7.7 leaves three choices unspecified:
-
•
The stopping criterion is not defined. The learner needs to stop when there are no input conditions, or when all of the examples have the same classification. A number of criteria have been suggested for stopping earlier:
-
–
Minimum child size: do not split more if one of the children will have fewer examples than a threshold.
-
–
Minimum number of examples at a node: stop splitting if there are fewer examples than some threshold. With a minimum child size, we know we can stop with fewer than twice the minimum child size, but the threshold may be higher than this.
-
–
The improvement of the criteria being optimized must be above a threshold. For example, the information gain may need to be above some threshold.
-
–
Maximum depth: do not split more if the depth reaches a maximum.
-
–
-
•
What should be returned at the leaves is not defined. This is a point estimate that ignores all of the input conditions (except the ones on the path that lead to this leaf). This prediction is typically the most likely classification, the median value, the mean value, or a probability distribution over the classifications. See Exercise 8.
-
•
Which condition to pick to split on is not defined. The aim is to pick a condition that will result in the smallest tree. The standard way to do this is to pick the myopically optimal or greedy optimal split; if the learner were only allowed one split, pick whichever condition would result in the best classification if that were the only split. For likelihood, entropy, or when minimizing the log loss, the myopically optimal split is the one that gives the maximum information gain. Sometimes information gain is used even when the optimality criterion is some other error measure.
Example 7.9.
In the running example of learning the user action from the data of Figure 7.1, suppose you want to maximize the likelihood of the prediction or, equivalently, minimize the log loss. In this example, we myopically choose a split that minimizes the log loss.
Without any splits, the optimal prediction on the training set is the empirical frequency. There are examples with and examples with , and so is predicted with probability 0.5. The log loss is equal to .
Consider splitting on . This partitions the examples into , , , , , , , , , , , with and , , , , , with , each of which is evenly split between the different user actions. The optimal prediction for each partition is again 0.5, and so the log loss after the split is again 1. In this case, finding out whether the author is known, by itself, provides no information about what the user action will be.
Splitting on partitions the examples into , , , , , , , , , with and , , , , , , , with . The examples with , contains examples with and examples with , thus the optimal prediction for these is to predict reads with probability . The examples with , have 2 and 6 . Thus the best prediction for these is to predict with probability 2/8. The log loss after the split is
Splitting on divides the examples into , , , , , , and , , , , , , , , , , . The former all agree on the value of and predict with probability 1. The user action divides the second set , and so the log loss is
Therefore, splitting on is better than splitting on or , when myopically optimizing the log loss.
In the algorithm of Figure 7.7, Boolean input features can be used directly as the conditions. Non-Boolean input features can be handled in two ways:
-
•
Expand the algorithm to allow multiway splits. To split on a multivalued variable, there would be a child for each value in the domain of the variable. This means that the representation of the decision tree becomes more complicated than the simple if-then-else form used for binary features. There are two main problems with this approach. The first is what to do with values of a feature for which there are no training examples. The second is that for most myopic splitting heuristics, including information gain, it is generally better to split on a variable with a larger domain because it produces more children and so can fit the data better than splitting on a feature with a smaller domain. However, splitting on a feature with a smaller domain keeps the representation more compact. A 4-way split, for example, is equivalent to 3 binary splits; they both result in 4 leaves. See Exercise 6.
-
•
Partition the domain of an input feature into two disjoint subsets, as with ordinal features or indicator variables
If the domain of input variable is totally ordered, a cut of the domain can be used as the condition. That is, the children could correspond to and for some value . To pick the optimal value for , sort the examples on the value of , and sweep through the examples to consider each split value and pick the best. See Exercise 7.
When the domain of is discrete and does not have a natural ordering, a split can be performed on arbitrary subsets of the domain. When the target is Boolean, each value of has a proportion of the target feature that is true. A myopically optimal split will be between values when the values are sorted according to this probability of the target feature.
A major problem of the preceding algorithm is overfitting the data. Overfitting occurs when the algorithm tries to fit distinctions that appear in the training data but do not appear in the test set. Overfitting is discussed more fully in Section 7.4.
There are two principal ways to overcome the problem of overfitting in decision trees:
-
•
Restrict the splitting to split only when the split is useful, such as only when the training-set error reduces by more than some threshold.
-
•
Allow unrestricted splitting and then prune the resulting tree where it makes unwarranted distinctions.
The second method often work better in practice. One reason is that it is possible that two features together predict well but one of them, by itself, is not very useful, as shown in the following example.
Example 7.10.
Matching pennies is a game where two coins are tossed and the player wins if both coins come up heads or both coins come up tails, and loses if the coins are different. Suppose the aim is to predict whether a game of matching pennies is won or not. The input features are , whether the first coin is heads or tails; , whether the second coin is heads or tails; and , whether there is cheering. The target feature, , is true when there is a win. Suppose cheering is correlated with winning. This example is tricky because by itself provides no information about , and by itself provides no information about . However, together they perfectly predict . A myopic split may first split on , because this provides the most myopic information. If all the agent is told is , this is much more useful than or . However, if the tree eventually splits on and , the split on is not needed. Pruning can remove as part of the tree, whereas stopping early will keep the split on .
A discussion of how to trade off model complexity and fit to the data is presented in Section 7.4.