Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
11.2.2 Unobserved Variables
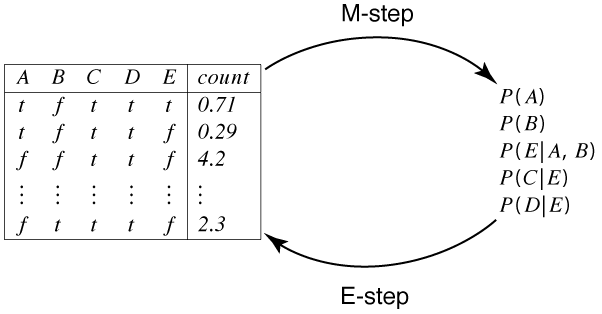
The next simplest case is one in which the model is given, but not all variables are observed. A hidden variable or a latent variable is a variable in the belief network models whose value is not observed. That is, there is no column in the data corresponding to that variable.
| Model | Data | → | Probabilities | |||||||||||||||||||||||||
 |
|
| ||||||||||||||||||||||||||
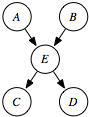
Note that, if E were missing from the model, the algorithm would have to learn P(A), P(B), P(C|AB), P(D|ABC), which has 14 parameters. The reason to introduce hidden variables is to make the model simpler and, therefore, less prone to overfitting.
The EM algorithm for learning belief networks with hidden variables is essentially the same as the EM algorithm for clustering. The E step can involve more complex probabilistic inference as, for each example, it infers the probability of the hidden variable(s) given the observed variables for that example. The M step of inferring the probabilities of the model from the augmented data is the same as the fully observable case discussed in the previous section, but, in the augmented data, the counts are not necessarily integers.