Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
8.4 Planning as a CSP
In forward planning, the search is constrained by the initial state and only uses the goal as a stopping criterion and as a source for heuristics. In regression planning, the search is constrained by the goal and only uses the start state as a stopping criterion and as a source for heuristics. It is possible to go forward and backward in the same planner by using the initial state to prune what is not reachable and the goal to prune what is not useful. This can be done by converting a planning problem to a constraint satisfaction problem (CSP) and using one of the CSP methods from Chapter 4.
For the CSP representation, it is also useful to describe the actions in terms of features - to have a factored representation of actions as well as a factored representation of states. The features representing actions are called action features and the features representing states are called state features.
- whether it will pick up coffee. Let PUC be a Boolean variable that is true when Rob picks up coffee.
- whether it will deliver coffee. Let DelC be a Boolean variable that is true when Rob delivers coffee.
- whether it will pick up mail. Let PUM be a Boolean variable that is true when Rob picks up mail.
- whether it will deliver mail. Let DelM be a Boolean variable that is true when Rob delivers mail.
- whether it moves. Let Move be a variable with domain {mc,mcc,nm} that specifies whether Rob moves clockwise, moves counterclockwise, or does not move (nm means "not move").
To construct a CSP from a planning problem, first choose a fixed horizon, which is the number of time steps over which to plan. Suppose this number is k. The CSP has the following variables:
- a variable for each state feature and each time from 0 to k. If there are n such features, there are n(k+1) such variables.
- a variable for each action feature for each time in the range 0 to k-1. These are called action variables. The action at time t represents the action that takes the agent from the state at time t to the state at time t+1.
There are a number of types of constraints:
- State constraints are constraints among variables at the same time step. These can include physical constraints on the state or can ensure that states that violate maintenance goals are forbidden.
- Precondition constraints between state variables at time t and action variables at time t specify constraints on what actions are available from a state.
- Effect constraints among state variables at time t, action variables at time t, and state variables at time t+1 constrain the values of the state variables at time t+1 in terms of the actions and the previous state.
- Action constraints specify which actions cannot co-occur. These are sometimes called mutual exclusion or mutex constraints.
- Initial-state constraints are constraints on the initial state (at time 0). These constrain the initial state to be the current state of the agent. If there is a unique initial state, it can be represented as a set of domain constraints on the state variables at time 0.
- Goal constraints constrain the final state to be a state that satisfies the achievement goal. These are domain constraints if the goal is for certain variables to have particular values at the final step, but they can also be more general constraints - for example, if two variables must have the same value.
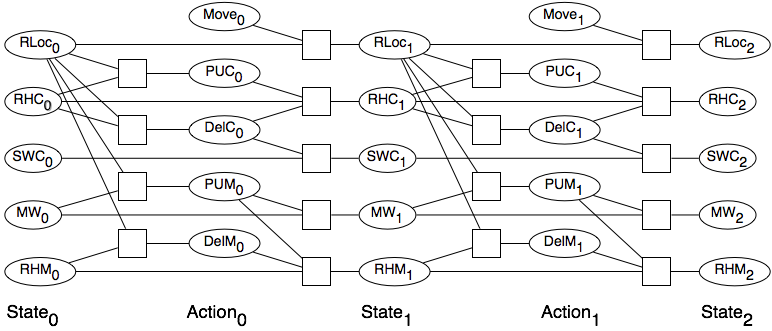
- RLoci
- - Rob's location
- RHCi
- - Rob has coffee
- SWCi
- - Sam wants coffee
- MWi
- - Mail is waiting
- RHMi
- - Rob has mail
- Movei
- - Rob's move action
- PUCi
- - Rob picks up coffee
- DelC
- - Rob delivers coffee
- PUMi
- - Rob picks up mail
- DelMi
- - Rob delivers mail
There are no domain constraints in this example. You could make a constraint that says Rob cannot carry both the mail and coffee, or that Rob cannot carry mail when there is mail waiting, if these were true in the domain. They are not included here.
The constraints to the left of the actions are the precondition constraints, which specify what values the action variables can take (i.e., what actions are available for each of the action variables). The Movei variables have no preconditions: all moves are available in all states. The PUMi variable, which specifies whether Rob can pick up mail, depends on Rob's location at time i (i.e., the value of RLoci) and whether there is mail waiting at time i (MWi). The negation of an action (e.g., PUMi=false, written as ¬pumi) is always available, assuming that the agent can choose not to perform an action. The action PUMi=true, written as pumi, is only available when the location is mr and MWi=true. When the precondition of an action is a conjunction, it can be written as a set of constraints, because the constraints in a CSP are implicitly conjoined. If the precondition is a more complex proposition, it can be represented as a constraint involving more than two variables.
The constraints to the left of the state variables at times 1 and later indicate the values of the state variables as a function of the previous state and the action. For example, the following constraint is among RHCi, DCi, PUCi, and whether the robot has coffee in the subsequent state, RHCi+1:
| RHCi | DCi | PUCi | RHCi+1 |
| true | true | true | true |
| true | true | false | false |
| true | false | true | true |
| true | false | false | true |
| false | true | true | true |
| false | true | false | false |
| false | false | true | true |
| false | false | false | false |
This table represents the same constraint as the rules of Example 8.4.
Initially, Sam wants coffee but the robot does not have coffee. This can be represented as two domain constraints: one on SWC0 and one on RHC0. The goal is that Sam no longer wants coffee. This can be represented as the domain constraint SWC2=false.
Just running arc consistency on this network results in RLoc0=cs (the robot has to start in the coffee shop), PUC0=true (the robot has to pick up coffee initially), Move0=mc (the robot has to move to the office), and DC1=true (the robot has to deliver coffee at time 1).
The CSP representation assumes a fixed planning horizon (i.e., a fixed number of steps). To find a plan over any number of steps, the algorithm can be run for a horizon of k=0, 1, 2, until a solution is found. For the stochastic local searching algorithm, it is possible to search multiple horizons at once, searching for all horizons, k from 0 to n, and allowing n to increase slowly. When solving the CSP using arc consistency and search, it may be possible to determine that trying a longer plan will not help. That is, by analyzing why no solution exists for a horizon of n steps, it may be possible to show that there can be no plan for any length greater than n. This will enable the planner to halt when there is no plan. See Exercise 8.12.
