Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
6.4.1 Variable Elimination for Belief Networks
This section gives an algorithm for finding the posterior distribution for a variable in an arbitrarily structured belief network. Many of the efficient exact methods can be seen as optimizations of this algorithm. This algorithm can be seen as a variant of variable elimination (VE) for constraint satisfaction problems (CSPs) or VE for soft constraints.
The algorithm is based on the notion that a belief network specifies a factorization of the joint probability distribution. Before we give the algorithm, we define factors and the operations that will be performed on them. Recall that P(X|Y) is a function from variables (or sets of variables) X and Y into the real numbers that, given a value for X and a value for Y, gives the conditional probability of the value for X, given the value for Y. This idea of a function of variables is generalized as the notion of a factor. The VE algorithm for belief networks manipulates factors to compute posterior probabilities.
A factor is a representation of a function from a tuple of random variables into a number. We will write factor f on variables X1,...,Xj as f(X1,...,Xj). The variables X1,...,Xj are the variables of the factor f, and f is a factor on X1,...,Xj.
Suppose f(X1,...,Xj) is a factor and each vi is an element of the domain of Xi. f(X1=v1,X2=v2,...,Xj=vj) is a number that is the value of f when each Xi has value vi. Some of the variables of a factor can be assigned to values to make a new factor on the other variables. For example, f(X1=v1,X2,...,Xj), sometimes written as f(X1,X2,...,Xj)X1=v1, where v1 is an element of the domain of variable X1, is a factor on X2,...,Xj.
Representations of Conditional Probabilities and Factors
A conditional probability distribution can be seen as a function of the variables involved. A factor is a representation of a function on variables; thus, a factor can be used to represent conditional probabilities.
When the variables have finite domains, these factors can be implemented as arrays. If there is an ordering of the variables (e.g., alphabetical) and the values in the domains are mapped into the non-negative integers, there is a canonical representation of each factor as a one-dimensional array that is indexed by natural numbers. Operations on factors can be implemented efficiently using such a representation. However, this form is not a good one to present to users because the structure of the conditional is lost. Factors do not have to be implemented as arrays. The tabular representation is often too large when there are many parents. Often, more structure exists in conditional probabilities that can be exploited.
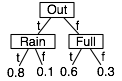
One such structure exploits context-specific independence, where one variable is conditionally independent of another, given a particular value of the third variable. For example, suppose the robot can go outside or get coffee. Whether it gets wet depends on whether there is rain in the context that it went out or on whether the cup was full if it got coffee. There are a number of ways to represent the conditional probability P(Wet|Out,Rain,Full) - for example as a decision tree, as rules with probabilities, or as tables with contexts:
wet ←out ∧rain: 0.8 wet ←out ∧∼rain: 0.1 wet ←∼out ∧full: 0.6 wet ←∼out ∧∼full: 0.3
out:
Rain Wet Prob t t 0.8 t f 0.2 f t 0.1 f f 0.9 ∼out:
Full Wet Prob t t 0.6 t f 0.4 f t 0.3 f f 0.7
Another common representation is a noisy or. For example, suppose the robot can get wet from rain, coffee, sprinkler, or kids. There can be a probability that it gets wet from rain if it rains, and a probability that it gets wet from coffee if it has coffee, and so on (these probabilities give the noise). The robot gets wet if it gets wet from one of them, giving the "or".
The next chapter explores other representations that can be used for conditional probabilities.
| X | Y | Z | val |
| t | t | t | 0.1 |
| t | t | f | 0.9 |
| t | f | t | 0.2 |
| t | f | f | 0.8 |
| f | t | t | 0.4 |
| f | t | f | 0.6 |
| f | f | t | 0.3 |
| f | f | f | 0.7 |
r(X=t,Y,Z)=
| Y | Z | val |
| t | t | 0.1 |
| t | f | 0.9 |
| f | t | 0.2 |
| f | f | 0.8 |
r(X=t,Y,Z=f)=
| Y | val |
| t | 0.9 |
| f | 0.8 |
r(X=t,Y=f,Z=f)=0.8
Factors can be multiplied together. Suppose f1 and f2 are factors, where f1 is a factor that contains variables X1,...,Xi and Y1,...,Yj, and f2 is a factor with variables Y1,...,Yj and Z1,...,Zk, where Y1,...,Yj are the variables in common to f1 and f2. The product of f1 and f2, written f1×f2, is a factor on the union of the variables, namely X1,...,Xi,Y1,...,Yj,Z1,...,Zk, defined by:
(f1 ×f2)(X1,...,Xi,Y1,...,Yj,Z1,...,Zk) = f1(X1,...,Xi,Y1,...,Yj) ×f2(Y1,...,Yj,Z1,...,Zk).
f1=
| |||||||||||||||
f2=
| |||||||||||||||
f1 ×f2=
| A | B | C | val |
| t | t | t | 0.03 |
| t | t | f | 0.07 |
| t | f | t | 0.54 |
| t | f | f | 0.36 |
| f | t | t | 0.06 |
| f | t | f | 0.14 |
| f | f | t | 0.48 |
| f | f | f | 0.32 |
The remaining operation is to sum out a variable in a factor. Given factor f(X1,...,Xj), summing out a variable, say X1, results in a factor on the other variables, X2,...,Xj, defined by
(∑X1 f)(X2,...,Xj) = f(X1=v1,X2,...,Xj)+ ···+ f(X1=vk,X2...,Xj),
where {v1,...,vk} is the set of possible values of variable X1.
| A | B | C | val |
| t | t | t | 0.03 |
| t | t | f | 0.07 |
| t | f | t | 0.54 |
| t | f | f | 0.36 |
| f | t | t | 0.06 |
| f | t | f | 0.14 |
| f | f | t | 0.48 |
| f | f | f | 0.32 |
∑B f3=
| A | C | val |
| t | t | 0.57 |
| t | f | 0.43 |
| f | t | 0.54 |
| f | f | 0.46 |
(∑B f3)(A=t,C=f) = f3(A=t,B=t,C=f)+f3(A=t,B=f,C=f) = 0.07+0.36 = 0.43
A conditional probability distribution P(X|Y1,...,Yj) can be seen as a factor f on X,Y1,...,Yj, where
f(X=u,Y1=v1,...,Yj=vj)=P(X=u|Y1=v1∧···∧Yj=vj).
Usually, humans prefer the P(·| ·) notation, but internally the computer just treats conditional probabilities as factors.
The belief network inference problem is the problem of computing the posterior distribution of a variable, given some evidence.
The problem of computing posterior probabilities can be reduced to the problem of computing the probability of conjunctions. Given evidence Y1=v1, ..., Yj=vj, and query variable Z:
P(Z|Y1=v1,...,Yj=vj) = ( P(Z,Y1=v1,...,Yj=vj))/(P(Y1=v1,...,Yj=vj)) = ( P(Z,Y1=v1,...,Yj=vj))/(∑z P(Z,Y1=v1,...,Yj=vj)).
So the agent computes the factor P(Z,Y1=v1,...,Yj=vj) and normalizes. Note that this is a factor only of Z; given a value for Z, it returns a number that is the probability of the conjunction of the evidence and the value for Z.
Suppose the variables of the belief network are X1,...,Xn. To compute the factor P(Z,Y1=v1,...,Yj=vj), sum out the other variables from the joint distribution. Suppose Z1,...,Zk is an enumeration of the other variables in the belief network - that is,
{Z1,...,Zk} = {X1,...,Xn} - {Z} - {Y1,...,Yj}.
The probability of Z conjoined with the evidence is
p(Z,Y1=v1,...,Yj=vj)=∑Zk···∑Z1 P(X1,...,Xn)Y1=v1,...,Yj=vj.
The order that the variables Zi are summed out is an elimination ordering.
Note how this is related to the possible worlds semantics of probability. There is a possible world for each assignment of a value to each variable. The joint probability distribution, P(X1,...,Xn), gives the probability (or measure) for each possible world. The VE algorithm thus selects the worlds with the observed values for the Yi's and sums over the possible worlds with the same value for Z. This corresponds to the definition of conditional probability. However, VE does this more efficiently than by summing over all of the worlds.
By the rule for conjunction of probabilities and the definition of a belief network,
P(X1,...,Xn) = P(X1|parents(X1))×···×P(Xn|parents(Xn)),
where parents(Xi) is the set of parents of variable Xi.
We have now reduced the belief network inference problem to a problem of summing out a set of variables from a product of factors. To solve this problem efficiently, we use the distribution law learned in high school: to compute a sum of products such as xy+xz efficiently, distribute out the common factors (here x), which results in x(y+z). This is the essence of the VE algorithm. We call the elements multiplied together "factors" because of the use of the term in algebra. Initially, the factors represent the conditional probability distributions, but the intermediate factors are just functions on variables that are created by adding and multiplying factors.
To compute the posterior distribution of a query variable given observations:
- Construct a factor for each conditional probability distribution.
- Eliminate each of the non-query variables:
- if the variable is observed, its value is set to the observed value in each of the factors in which the variable appears,
- otherwise the variable is summed out.
- Multiply the remaining factors and normalize.
To sum out a variable Z from a product f1,...,fk of factors, first partition the factors into those that do not contain Z, say f1,...,fi, and those that contain Z, fi+1,...,fk; then distribute the common factors out of the sum:
∑Z f1×···×fk = f1×···×fi×(∑Z fi+1×···×fk).
VE explicitly constructs a representation (in terms of a multidimensional array, a tree, or a set of rules) of the rightmost factor.
2: Inputs
3: Vs: set of variables
4: Ps: set of factors representing the conditional probabilities
5: O: set of observations of values on some of the variables
6: Q: a query variable
7: Output
8: posterior distribution on Q
9: Local
10: Fs: a set of factors
11: Fs ←Ps
12: for each X∈Vs-{Q} using some elimination ordering do
13: if (X is observed) then
14: for each F ∈Fs that involves X do
15: set X in F to its observed value in O
16: project F onto remaining variables
17: else
18: Rs←{F ∈Fs: F involves X}
19: let T be the product of the factors in Rs
20: N ←∑X T
21: Fs←Fs \ Rs∪{N}
22: let T be the product of the factors in Fs
23: N ←∑Q T
24: return T/N
Figure 6.8 gives pseudocode for the VE algorithm. The elimination ordering can be given a priori or can be computed on the fly. It is worthwhile to select observed variables first in the elimination ordering, because eliminating these simplifies the problem.
This assumes that the query variable is not observed. If it is observed to have a particular value, its posterior probability is just 1 for the observed value and 0 for the other values.
P(Tampering|Smoke=true ∧Report=true).
After eliminating the observed variables, Smoke and Report, the following factors remain:
Conditional Probability Factor P(Tampering) f0(Tampering) P(Fire) f1(Fire) P(Alarm|Tampering,Fire) f2(Tampering, Fire, Alarm) P(Smoke=yes|Fire) f3(Fire) P(Leaving|Alarm) f4(Alarm, Leaving) P(Report=yes|Leaving) f5(Leaving)
The algorithm ignores the conditional probability reading and just works with the factors. The intermediate factors do not always represent a conditional probability.
Suppose Fire is selected next in the elimination ordering. To eliminate Fire, collect all of the factors containing Fire - f1(Fire), f2(Tampering, Fire, Alarm), and f3(Fire) - multiply them together, and sum out Fire from the resulting factor. Call this factor F6(Tampering,Alarm). At this stage, the following factors remain:
f0(Tampering), f4(Alarm, Leaving), f5(Leaving), f6(Tampering,Alarm).
Suppose Alarm is eliminated next. VE multiplies the factors containing Alarm and sums out Alarm from the product, giving a factor, call it f7:
f7(Tampering,Leaving) = ∑Alarm f4(Alarm,Leaving) ×f6(Tampering,Alarm)
It then has the following factors:
f0(Tampering), f5(Leaving), f7(Tampering,Leaving).
Eliminating Leaving results in the factor
f8(Tampering) = ∑Leaving f5(Leaving) ×f7(Tampering,Leaving).
To determine the distribution over Tampering, multiply the remaining factors, giving
f9(Tampering) = f0(Tampering) ×f8(Tampering).
The posterior distribution over tampering is given by
(f9(Tampering))/(∑Tampering f9(Tampering)) .
Note that the denominator is the prior probability of the evidence.
P(Alarm|Fire=true).
When Fire is eliminated, the factor P(Fire) becomes a factor of no variables; it is just a number, P(Fire=true).
Suppose Report is eliminated next. It is in one factor, which represents P(Report|Leaving). Summing over all of the values of Report gives a factor on Leaving, all of whose values are 1. This is because P(Report=true|Leaving=v)+P(Report=false|Leaving=v) = 1 for any value v of Leaving.
Similarly, if you eliminate Leaving next, you multiply a factor that is all 1 by a factor representing P(Leaving|Alarm) and sum out Leaving. This, again, results in a factor all of whose values are 1.
Similarly, eliminating Smoke results in a factor of no variables, whose value is 1. Note that even if smoke had been observed, eliminating smoke would result in a factor of no variables, which would not affect the posterior distribution on Alarm.
Eventually, there is only the factor on Alarm that represents its prior probability and a constant factor that will cancel in the normalization.
The complexity of the algorithm depends on a measure of complexity of the network. The size of a tabular representation of a factor is exponential in the number of variables in the factor. The treewidth of a network, given an elimination ordering, is the maximum number of variables in a factor created by summing out a variable, given the elimination ordering. The treewidth of a belief network is the minimum treewidth over all elimination orderings. The treewidth depends only on the graph structure and is a measure of the sparseness of the graph. The complexity of VE is exponential in the treewidth and linear in the number of variables. Finding the elimination ordering with minimum treewidth is NP-hard, but there are some good elimination ordering heuristics, as discussed for CSP VE.
There are two main ways to speed up this algorithm. Irrelevant variables can be pruned, given the observations and the query. Alternatively, it is possible to compile the graph into a secondary structure that allows for caching of values.
