Artificial
Intelligence 3E
foundations of computational agents
6.4 Planning as a CSP
In forward planning, the search is constrained by the initial state and only uses the goal as a stopping criterion and as a source for heuristics. In regression planning, the search is constrained by the goal and only uses the start state as a stopping criterion and as a source for heuristics. By converting the problem to a constraint satisfaction problem (CSP), the initial state can be used to prune what is not reachable and the goal to prune what is not useful. The CSP will be defined for a finite number of steps; the number of steps can be adjusted to find the shortest plan. Any of the CSP methods from Chapter 4 can then be used to solve the CSP and thus find a plan.
To construct a CSP from a planning problem, first choose a fixed planning horizon, which is the number of time steps over which to plan. Suppose the horizon is . The CSP has the following variables:
-
•
A state variable for each feature and each time from 0 to . If there are features for a horizon of , there are state variables. The domain of the state variable is the domain of the corresponding feature.
-
•
An action variable, , for each time in the range 0 to . The domain of is the set of all possible actions. The value of represents the action that takes the agent from the state at time to the state at time .
There are several types of constraints:
-
•
A precondition constraint between a state variable at time and the variable constrains what actions are legal at time .
-
•
An effect constraint between and a state variable at time constrains the values of a state variable that is a direct effect of the action.
-
•
A frame constraint among a state variable at time , the variable , and the corresponding state variable at time specifies when the variable that does not change as a result of an action has the same value before and after the action.
-
•
An initial-state constraint constrains a variable on the initial state (at time 0). The initial state is represented as a set of domain constraints on the state variables at time .
-
•
A goal constraint constrains the final state to be a state that satisfies the achievement goal. These are domain constraints on the variables that appear in the goal.
-
•
A state constraint is a constraint among variables at the same time step. These can include physical constraints on the state or can ensure that states that violate maintenance goals are forbidden. This is extra knowledge beyond the power of the feature-based or STRIPS representations of the action.
The STRIPS representation gives precondition, effect, and frame constraints for each time as follows:
-
•
For each in the precondition of action , there is a precondition constraint
that specifies that if the action is to be , must have value immediately before. This constraint is violated when and , and thus is equivalent to .
-
•
For each in the effect of action , there is an effect constraint
which is violated when , and thus is equivalent to .
-
•
For each , there is a frame constraint, where is the set of actions that include in the effect of the action:
which specifies that the feature has the same value before and after any action that does not affect .
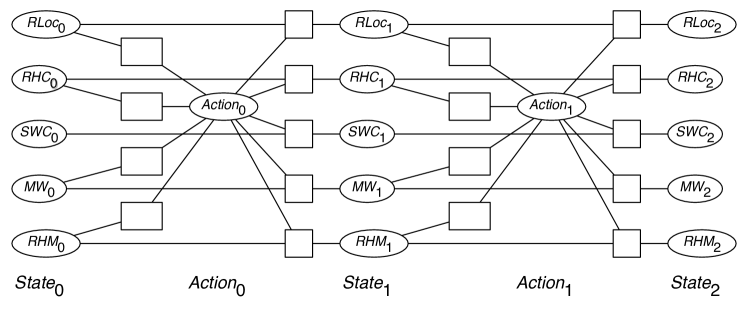
| – Rob’s location – Rob has coffee – Sam wants coffee – Mail is waiting – Rob has mail – Rob’s action |
Example 6.14.
Figure 6.4 shows a CSP representation of the delivery robot example, with a planning horizon of . There are three copies of the state variables: one at time 0, the initial state; one at time 1; and one at time 2, the final state. There are action variables for times 0 and 1.
Precondition constraints: The constraints to the left of the action variable for each time are the precondition constraints. There is a separate constraint for each element of the precondition of the action.
The precondition for the action deliver coffee, , is ; the robot has to be in the office and it must have coffee. Thus there are two precondition constraints for delivers coffee:
Effect constraints: The effect of delivering coffee () is . Therefore there are two effect constraints:
Frame constraints: Rob has mail () is not one of the effects of delivering coffee (). Thus there is a frame constraint:
which is violated when .
Example 6.15.
Consider finding a plan to get Sam coffee, where initially, Sam wants coffee but the robot does not have coffee. This can be represented as initial-state constraints: and .
With a planning horizon of 2, the goal is represented as the domain constraint , and there is no solution.
With a planning horizon of 3, the goal is represented as the domain constraint . This has many solutions, all with (the robot has to start in the coffee shop), (the robot has to pick up coffee initially), (the robot has to move to the office), and (the robot has to deliver coffee at time 2).
The CSP representation assumes a fixed planning horizon (i.e., a fixed number of steps). To find a plan over any number of steps, the algorithm can be run for a horizon of , , , … until a solution is found. For the stochastic local search algorithm, it is possible to search multiple horizons at once, searching for all horizons, from 0 to , and allowing to vary slowly. When solving the CSP using arc consistency and domain splitting, it is sometimes possible to determine that trying a longer plan will not help. That is, by analyzing why no solution exists for a horizon of steps, it may be possible to show that there can be no plan for any length greater than . This will enable the planner to halt when there is no plan. See Exercise 6.10.
6.4.1 Action Features
So far we have assumed that actions are atomic and that an agent can only do one action at any time. For the CSP representation, it can be useful to describe the actions in terms of features – to have a factored representation of actions as well as a factored representation of states. The features representing actions are called action features and the features representing states are called state features. The action features can be considered as actions in themselves that are carried out in the same time step.
In this case, there can be an extra set of constraints called action constraints to specify which action features cannot co-occur. These are sometimes called mutual exclusion or mutex constraints.
Example 6.16.
Another way to model the actions of Example 6.1 is that, at each step, Rob gets to choose
-
•
whether it will pick up coffee – let be a Boolean variable that is true when Rob picks up coffee
-
•
whether it will deliver coffee – let be a Boolean variable that is true when Rob delivers coffee
-
•
whether it will pick up mail – let be a Boolean variable that is true when Rob picks up mail
-
•
whether it will deliver mail – let be a Boolean variable that is true when Rob delivers mail
-
•
whether it moves. Let be a variable with domain that specifies whether Rob moves clockwise, moves counterclockwise, or does not move ( means “not move”).
Thus the agent can be seen as doing more than one action in a single stage. For some of the actions at the same stage, the robot can do them in any order, such as delivering coffee and delivering mail. Some of the actions at the same stage need to be carried out in a particular order, for example, the agent must move after the other actions.
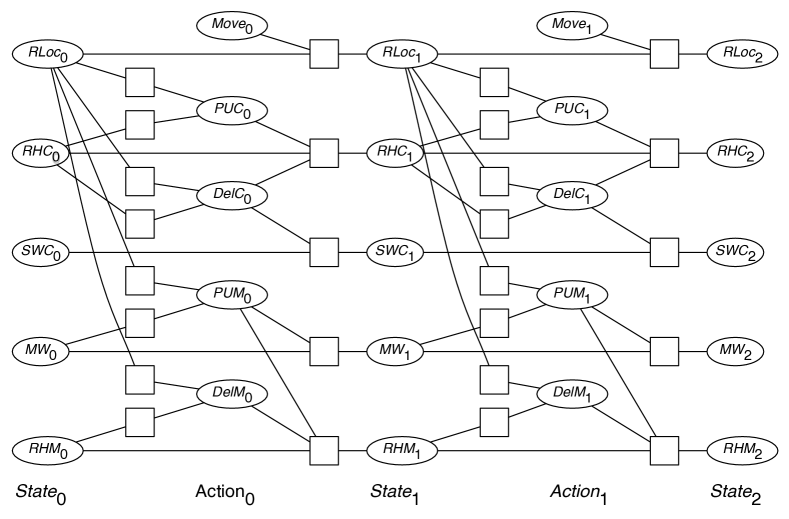
| – Rob’s location – Rob has coffee – Sam wants coffee – Mail is waiting – Rob has mail – Rob’s move action – Rob picks up coffee – Rob delivers coffee – Rob picks up mail – Rob delivers mail |
Example 6.17.
Consider finding a plan to get Sam coffee, where initially, Sam wants coffee but the robot does not have coffee. The initial state can be represented as two domain constraints: and . The goal is that Sam no longer wants coffee, .
With a planning horizon of 2, the CSP is shown in Figure 6.5. The goal is represented as the domain constraint , there is a solution (the robot has to start in the coffee shop), (the robot has to pick up coffee initially), (the robot has to move to the office), and (the robot has to deliver coffee at time 1).
Note that in the representation without factored actions, the problem cannot be solved with a horizon of 2; it requires a horizon of 3, as there are no concurrent actions.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.