Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
11.3 Computing Strategies with Perfect Information
Dimensions: flat, states, indefinite horizon, fully observable, deterministic, utility, non-learning, multiple agents, offline, perfect rationality
The equivalent to full observability with multiple agents is called perfect information. In perfect-information games, agents act sequentially and, when an agent has to act, it gets to observe the state of the world before deciding what to do. Each agent acts to maximize its own utility.
A perfect-information game can be represented as an extensive form game where the information sets all contain a single node. They can also be represented as a multiagent decision network where the decision nodes are totally ordered and, for each decision node, the parents of that decision node include the preceding decision node and all of their parents (so they are multiagent counterpart of no-forgetting decision networks).
Perfect-information games are solvable in a manner similar to fully observable single-agent systems. The can be solved backward, from the last decisions to the first, using dynamic programming or forward using search. The difference from the single-agent case is that the multiagent algorithm maintains a utility for each agent and, for each move, it selects an action that maximizes the utility of the agent making the move. The dynamic programming variant, called backward induction, starts from the end of the game, computing and caching the values and the plan of each node for each agent. It essentially follows the definition of the utility of a node for each agent, where the agent who controls the node gets to choose the action that maximizes its utility.
Example 11.6.
Consider the sharing game of Figure 11.2. For each of the nodes labeled with Barb, she gets to choose the value that maximizes her utility. Thus, she will choose “yes” for the right two nodes she controls, and would choose either for the leftmost node she controls. Suppose she chooses “no” for this node; then Andy gets to choose one of his actions: has utility 0 for him, has utility 1, and has utility 0, so he chooses to share.
In the case where two agents are competing so that a positive reward for one is a negative reward for the other agent, we have a two-agent zero-sum game. The value of such a game can be characterized by a single number that one agent is trying to maximize and the other agent is trying to minimize. Having a single value for a two-agent zero-sum game leads to a minimax strategy. Each node is either a MAX node, if it is controlled by the agent trying to maximize, or is a MIN node if it is controlled by the agent trying to minimize.
Backward induction could be used to find the optimal minimax strategy. From the bottom up, backward induction maximizes at MAX nodes and minimizes at MIN nodes. However, backward induction requires a traversal of the whole game tree. It is possible to prune part of the search tree by showing that some part of the tree will never be part of an optimal play.
Example 11.7.
Consider searching in the game tree of Figure 11.5. In this figure, the square MAX nodes are controlled by the maximizing agent, and the round MIN nodes are controlled by the minimizing agent.
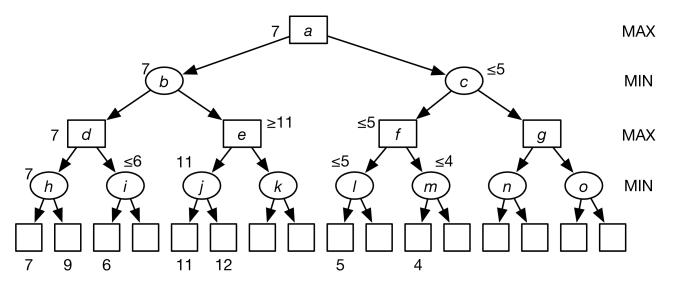
Suppose the values of the leaf nodes are given or are computed given the definition of the game. The numbers at the bottom show some of these values. The other values are irrelevant, as we show here. Suppose we are doing a left-first depth-first traversal of this tree. The value of node is 7, because it is the minimum of 7 and 9. Just by considering the leftmost child of with a value of , we know that the value of is less than or equal to 6. Therefore, at node , the maximizing agent will go left. We do not have to evaluate the other child of . Similarly, the value of is 11, so the value of is at least 11, and so the minimizing agent at node will choose to go left.
The value of is less than or equal to 5, and the value of is less than or equal to 4; thus, the value of is less than or equal to , so the value of will be less than or equal to 5. So, at , the maximizing agent will choose to go left. Notice that this argument did not depend on the values of the unnumbered leaves. Moreover, it did not depend on the size of the subtrees that were not explored.
The previous example analyzed what can be pruned. Minimax with alpha-beta (-) pruning is a depth-first search algorithm that prunes by passing pruning information down in terms of parameters and . In this depth-first search, a node has a score, which has been obtained from (some of) its descendants.
The parameter is used to prune MIN nodes. Initially, it is the highest current value for all MAX ancestors of the current node. Any MIN node whose current value is less than or equal to its value does not have to be explored further. This cutoff was used to prune the other descendants of nodes , , and in the previous example.
The dual parameter is used to prune MAX nodes.
The minimax algorithm with - pruning is given in Figure 11.6. It is called, initially, with
where is the root node. It returns a pair of the value for the node and a path of choices that is best for each agent the results in this path. (Note that this path does not include .) Line 13 performs pruning; at this stage the algorithm knows that the current path will never be chosen, and so return a current score. Similarly, line 22 performs -pruning. Line 17 and line 26 concatenate to the path, as it has found a best path for the agent. In this algorithm, the path “” is sometimes returned for non-leaf nodes; this only occurs when the algorithm has determined this path will not be used.
Example 11.8.
Consider running on the tree of Figure 11.5. We will show the recursive calls (and the values returned but not the paths.) Initially, it calls
which then calls, in turn,
This last call finds the minimum of both of its children and returns . Next the procedure calls
which then gets the value for the first of ’s children, which has value . Because , it returns . The call to then returns , and it calls
Node ’s first child returns and, because , it returns . Then returns , and the call to calls
which in turn calls
which eventually returns 5, and so the call to returns 5, and the whole procedure returns 7.
By keeping track of the values, the maximizing agent knows to go left at , then the minimizing agent will go left at , and so on.
The amount of pruning provided by this algorithm depends on the ordering of the children of each node. It works best if a highest-valued child of a MAX node is selected first and if a lowest-valued child of a MIN node is returned first. In implementations of real games, much of the effort is made to try to ensure this ordering.
Most real games are too big to carry out minimax search, even with - pruning. For these games, instead of only stopping at leaf nodes, it is possible to stop at any node. The value returned at the node where the algorithm stops is an estimate of the value for this node. The function used to estimate the value is an evaluation function. Much work goes into finding good evaluation functions. There is a trade-off between the amount of computation required to compute the evaluation function and the size of the search space that can be explored in any given time. It is an empirical question as to the best compromise between a complex evaluation function and a large search space.