Artificial
Intelligence 3E
foundations of computational agents
9.3 Belief Networks
The notion of conditional independence is used to give a concise representation of many domains. The idea is that, given a random variable , there may be a few variables that directly affect the ’s value, in the sense that is conditionally independent of other variables given these variables. The set of locally affecting variables is called the Markov blanket. This locality is exploited in a belief network.
A belief network is a directed acyclic graph representing conditional dependence among a set of random variables. The random variables are the nodes. The arcs represent direct dependence. The conditional independence implied by a belief network is determined by an ordering of the variables; each variable is independent of its predecessors in the total ordering given a subset of the predecessors called its parents. Independence in the graph is indicated by missing arcs.
To define a belief network on a set of random variables, , first select a total ordering of the variables, say, . The chain rule (Proposition 9.1.2) shows how to decompose a conjunction into conditional probabilities:
Or, in terms of random variables:
| (9.1) |
Define the parents of random variable , written , to be a minimal set of predecessors of in the total ordering such that the other predecessors of are conditionally independent of given . Thus probabilistically depends on each of its parents, but is independent of its other predecessors. That is, such that
This conditional independence characterizes a belief network.
When there are multiple minimal sets of predecessors satisfying this condition, any minimal set may be chosen to be the parents. There can be more than one minimal set only when some of the predecessors are deterministic functions of others.
Putting the chain rule and the definition of parents together gives
The probability over all of the variables, , is called the joint probability distribution. A belief network defines a factorization of the joint probability distribution into a product of conditional probabilities.
A belief network, also called a Bayesian network, is an acyclic directed graph (DAG), where the nodes are random variables. There is an arc from each element of into . Associated with the belief network is a set of conditional probability distributions that specify the conditional probability of each variable given its parents (which includes the prior probabilities of those variables with no parents).
Thus, a belief network consists of
-
•
a DAG, where each node is labeled by a random variable
-
•
a domain for each random variable, and
-
•
a set of conditional probability distributions giving for each variable .
A belief network is acyclic by construction. How the chain rule decomposes a conjunction depends on the ordering of the variables. Different orderings can result in different belief networks. In particular, which variables are eligible to be parents depends on the ordering, as only predecessors in the ordering can be parents. Some of the orderings may result in networks with fewer arcs than other orderings.
Example 9.11.
Consider the four variables of Example 9.10, with the ordering: , , , . Consider the variables in order. does not have any predecessors in the ordering, so it has no parents, thus . is independent of , and so it too has no parents. depends on both and , so
is independent of and given and so
The corresponding belief network is given in Figure 9.2.
This graph defines the decomposition of the joint distribution:
In the examples below, the domains of the variables are simple, for example the domain of may be or it could be the actual text answers.
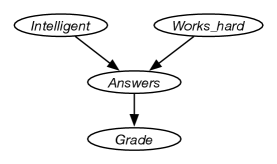
The independence of a belief network, according to the definition of parents, is that each variable is independent of all of the variables that are not descendants of the variable (its non-descendants) given the variable’s parents.
9.3.1 Observations and Queries
A belief network specifies a joint probability distribution from which arbitrary conditional probabilities can be derived. The most common probabilistic inference task – the task required for decision making – is to compute the posterior distribution of a query variable, or variables, given some evidence, where the evidence is a conjunction of assignment of values to some of the variables.
Example 9.12.
Before there are any observations, the distribution over intelligence is , which is provided as part of the network. To determine the distribution over grades, , requires inference.
If a grade of is observed, the posterior distribution of is given by
If it was also observed that is false, the posterior distribution of is
Although and are independent given no observations, they are dependent given the grade. This might explain why some people claim they did not work hard to get a good grade; it increases the probability they are intelligent.
9.3.2 Constructing Belief Networks
To represent a domain in a belief network, the designer of a network must consider the following questions.
-
•
What are the relevant variables? In particular, the designer must consider:
-
–
What the agent may observe in the domain. Each feature that may be observed should be a variable, because the agent must be able to condition on all of its observations.
-
–
What information the agent is interested in knowing the posterior probability of. Each of these features should be made into a variable that can be queried.
-
–
Other hidden variables or latent variables that will not be observed or queried but make the model simpler. These variables either account for dependencies, reduce the size of the specification of the conditional probabilities, or better model how the world is assumed to work.
-
–
-
•
What values should these variables take? This involves considering the level of detail at which the agent should reason to answer the sorts of queries that will be encountered.
For each variable, the designer should specify what it means to take each value in its domain. What must be true in the world for a (non-hidden) variable to have a particular value should satisfy the clarity principle: an omniscient agent should be able to know the value of a variable. It is a good idea to explicitly document the meaning of all variables and their possible values. The only time the designer may not want to do this is for hidden variables whose values the agent will want to learn from data [see Section 10.4.1].
-
•
What is the relationship between the variables? This should be expressed by adding arcs in the graph to define the parent relation.
-
•
How does the distribution of a variable depend on its parents? This is expressed in terms of the conditional probability distributions.
Example 9.13.
Suppose you want to use the diagnostic assistant to diagnose whether there is a fire in a building and whether there has been some tampering with equipment based on noisy sensor information and possibly conflicting explanations of what could be going on. The agent receives a report from Sam about whether everyone is leaving the building. Suppose Sam’s report is noisy: Sam sometimes reports leaving when there is no exodus (a false positive), and sometimes does not report when everyone is leaving (a false negative). Suppose that leaving only depends on the fire alarm going off. Either tampering or fire could affect the alarm. Whether there is smoke only depends on whether there is fire.
Suppose you use the following variables in the following order:
-
•
is true when there is tampering with the alarm.
-
•
is true when there is a fire.
-
•
is true when the alarm sounds.
-
•
is true when there is smoke.
-
•
is true if there are many people leaving the building at once.
-
•
is true if Sam reports people leaving. is false if there is no report of leaving.
Assume the following conditional independencies:
-
•
is conditionally independent of (given no other information).
-
•
depends on both and . This is making no independence assumptions about how depends on its predecessors given this variable ordering.
-
•
depends only on and is conditionally independent of and given whether there is .
-
•
only depends on and not directly on or or . That is, is conditionally independent of the other variables given .
-
•
only directly depends on .
The belief network of Figure 9.3 expresses these dependencies.
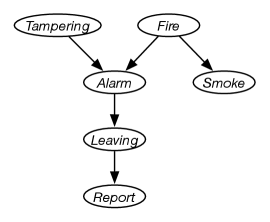
This network represents the factorization
Note that the alarm is not a smoke alarm, which would be affected by the smoke, and not directly by the fire, but rather it is a heat alarm that is directly affected by the fire. This is made explicit in the model in that is independent of given .
You also must define the domain of each variable. Assume that the variables are Boolean; that is, they have domain . We use the lower-case variant of the variable to represent the true value and use negation for the false value. Thus, for example, is written as , and is written as .
The examples that follow assume the following conditional probabilities:
Before any evidence arrives, the probability is given by the priors. The following probabilities follow from the model (all of the numbers here are to about three decimal places):
Observing a report gives the following:
As expected, the probabilities of both and are increased by the report. Because the probability of is increased, so is the probability of .
Suppose instead that alone was observed:
Note that the probability of is not affected by observing ; however, the probabilities of and are increased.
Suppose that both and were observed:
Observing both makes even more likely. However, in the context of , the presence of makes less likely. This is because is explained away by , which is now more likely.
Suppose instead that , but not , was observed:
In the context of , becomes much less likely and so the probability of increases to explain .
This example illustrates how the belief net independence assumption gives commonsense conclusions and also demonstrates how explaining away is a consequence of the independence assumption of a belief network.
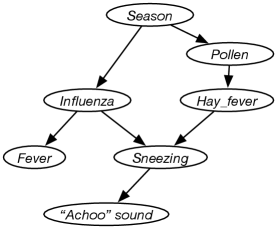
Example 9.14.
Consider the problem of diagnosing why someone is sneezing and perhaps has a fever. Sneezing could be because of influenza or because of hay fever. They are not independent, but are correlated due to the season. Suppose hay fever depends on the season because it depends on the amount of pollen, which in turn depends on the season. The agent does not get to observe sneezing directly, but rather observed just the “Achoo” sound. Suppose fever depends directly on influenza. These dependency considerations lead to the belief network of Figure 9.4.
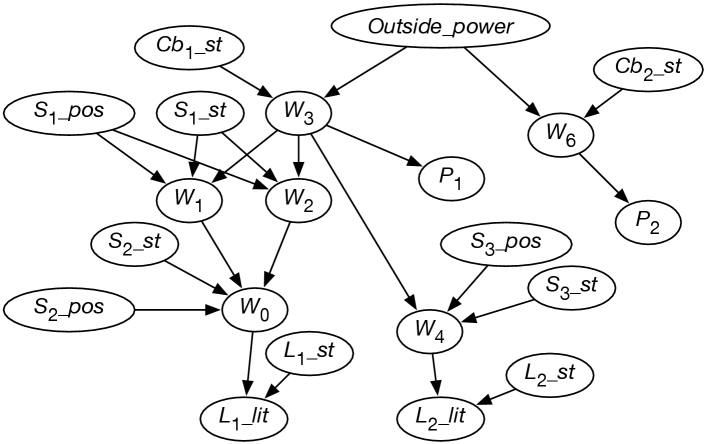
-
•
For each wire , there is a random variable, , with domain , which denotes whether there is power in wire . means wire has power. means there is no power in wire .
-
•
with domain denotes whether there is power coming into the building.
-
•
For each switch , variable denotes the position of . It has domain .
-
•
For each switch , variable denotes the state of switch . It has domain . means switch is working normally. means switch is installed upside-down. means switch is shorted and acting as a wire. means switch is broken and does not allow electricity to flow.
-
•
For each circuit breaker , variable has domain . means power could flow through and means power could not flow through .
-
•
For each light , variable with domain denotes the state of the light. means light will light if powered, means light intermittently lights if powered, and means light does not work.
Example 9.15.
Consider the wiring example of Figure 1.6. Let’s have variables for whether lights are lit, for the switch positions, for whether lights and switches are faulty or not, and for whether there is power in the wires. The variables are defined in Figure 9.5.
Let’s try to order the variables so that each variable has few parents. In this case there seems to be a natural causal order where, for example, the variable for whether a light is lit comes after variables for whether the light is working and whether there is power coming into the light.
Whether light is lit depends only on whether there is power in wire and whether light is working properly. Other variables, such as the position of switch , whether light is lit, or who is the Queen of Canada, are irrelevant. Thus, the parents of are whether there is power in wire (variable ), and the status of light (variable ); see Figure 9.5 for the meaning of the variables.
Consider variable , which represents whether there is power in wire . If you knew whether there was power in wires and , and knew the position of switch and whether the switch was working properly, the value of the other variables (other than ) would not affect the belief in whether there is power in wire . Thus, the parents of should be , , , and .
Figure 9.5 shows the resulting belief network after the independence of each variable has been considered. The belief network also contains the domains of the variables and conditional probabilities of each variable given its parents.
Note the independence assumption embedded in this model. The DAG specifies that the lights, switches, and circuit breakers break independently. To model dependencies among how the switches break, you could add more arcs and perhaps more variables. For example, if some lights do not break independently because they come from the same batch, you could add an extra node modeling the batch, and whether it is a good batch or a bad batch, which is made a parent of the variables for each light from that batch. When you have evidence that one light is broken, the probability that the batch is bad may increase and thus make it more likely that other lights from that batch are broken. If you are not sure whether the lights are indeed from the same batch, you could add variables representing this, too. The important point is that the belief network provides a specification of independence that lets us model dependencies in a natural and direct manner.
The model implies that there is no possibility of shorts in the wires or that the house is wired differently from the diagram. For example, it implies that cannot be shorted to so that wire gets power from wire . You could add extra dependencies that let each possible short be modeled. An alternative is to add an extra node that indicates that the model is appropriate. Arcs from this node would lead to each variable representing power in a wire and to each light. When the model is appropriate, you could use the probabilities of Example 9.15. When the model is inappropriate, you could, for example, specify that each wire and light works at random. When there are weird observations that do not fit in with the original model – they are impossible or extremely unlikely given the model – the probability that the model is inappropriate will increase.
9.3.3 Representing Conditional Probabilities and Factors
A factor is a function of a set of variables; the variables on which it depends are the scope of the factor. Given an assignment of a value to each variable in the scope, the factor evaluates to a number.
A conditional probability is a factor representing , which is a function from the variables into nonnegative numbers. It must satisfy the constraints that for each assignment of values to all of , the values for sum to 1. That is, given values for all of the variables, the function returns a number that satisfies the constraint
| (9.2) |
The following gives a number of ways of representing conditional probabilities, and other factors.
Conditional Probability Tables
A representation for a conditional probability that explicitly stores a value for each assignment to the variables is called a conditional probability table or CPT. This can be done whenever there is a finite set of variables with finite domains. The space used is exponential in the number of variables; the size of the table is the product of the sizes of the domains of the variables in the scope.
One such representation is to use a multidimensional table, storing in (using Python’s notation for arrays, and exploiting its ambiguity of arrays and dictionaries).
| false | false | 0.0001 |
| false | true | 0.85 |
| true | false | 0.99 |
| true | true | 0.5 |
Example 9.16.
Figure 9.6 shows the conditional probabilities for . The probability for being false can be computed from the given probabilities, for example:
Given a total ordering of the variables, , the values mapped to the nonnegative integers; false to 0 and true to 1.
of Figure 9.6 can be represented as the Python array
Given particular values of , where , , and are each 0 or 1, the value can be found at . If the domain of a variable is not of the form , a dictionary can be used. Other languages have different syntaxes.
There are a number of refinements, which use different space-time tradeoffs, including the following.
-
•
Tables can be implemented as one-dimensional arrays. Given an ordering of the variables (e.g., alphabetical) and an ordering for the values, and using a mapping from the values into nonnegative integers, there is a unique representation using the lexical ordering of each factor as a one-dimensional array that is indexed by natural numbers. This is a space-efficient way to store a table.
-
•
If the child variable is treated the same as the parent variables, the information is redundant; more numbers are specified than is required. One way to handle this is to store the probability for all-but-one of the values of the child, . The probability of the other value can be computed as 1 minus the sum of other values for a set of parents. In particular, if is Boolean, you only need to represent the probability for one value, say given the parents; the probability for can be computed from this.
-
•
It is also possible to store unnormalized probabilities, which are nonnegative numbers that are proportional to the probability. The probability is computed by dividing each value by the sum of the values. This is common when the unnormalized probabilities are counts [see Section 10.2.1].
Decision Trees
The tabular representation of conditional probabilities can be enormous when there are many parents. There is often insufficient evidence – either from data or from experts – to provide all the numbers required. Fortunately, there is often structure in conditional probabilities which can be exploited.
One such structure exploits context-specific independence, where one variable is conditionally independent of another, given particular values for some other variables.
Example 9.17.
Suppose a robot can go outside or get coffee, so has domain . Whether it gets wet (variable ) depends on whether there is rain (variable ) in the context that it went out or on whether the cup was full (variable ) if it got coffee. Thus is independent of given context , but is dependent on given contexts . Also, is independent of given , but is dependent on given .
A conditional probability table that represents such independencies is shown in Figure 9.7.
| go_out | false | false | 0.1 |
| go_out | false | true | 0.1 |
| go_out | true | false | 0.8 |
| go_out | true | true | 0.8 |
| get_coffee | false | false | 0.3 |
| get_coffee | false | true | 0.6 |
| get_coffee | true | false | 0.3 |
| get_coffee | true | true | 0.6 |
Context-specific independence may be exploited in a representation by not requiring numbers that are not needed. A simple representation for conditional probabilities that models context-specific independence is a decision tree, where the parents in a belief network correspond to the input features that form the splits, and the child corresponds to the target feature. Each leaf of the decision tree contains a probability distribution over the child variable.
Example 9.18.
The conditional probability of Figure 9.7 could be represented as a decision tree, where the number at the leaf is the probability for :
![[Uncaptioned image]](x172.png)
How to learn a decision tree from data was explored in Section 7.3.1. Context-specific inference can be exploited in probabilistic inference because a factor represented by a decision tree can be evaluated in an assignment when the values down a path in the tree hold; you don’t need to know the value of all parent variables.
Deterministic System with Noisy Inputs
An alternative representation of conditional distributions is in terms of a deterministic system, with probabilistic inputs. The deterministic system can range from a logical formula to a program. The inputs to the system are the parent variables and stochastic inputs. The stochastic inputs – often called noise variables or exogenous variables – can be considered as random variables that are unconditionally independent of each other. There is a deterministic system that defines the non-leaf variables of the belief network, the endogenous variables, as a deterministic function of the exogenous variables and the parents.
When the deterministic system is Clark’s completion of a logic program, it is known as probabilistic logic programming and when the deterministic system is a program, it is known as probabilistic programming. When the deterministic system is specified by a logical formula, the probabilistic inference is known as weighted model counting.
Example 9.19.
The decision tree of Example 9.7 for the conditional distribution of Figure 9.6 can be represented as the logical formula
where the are independent noise variables, with
So if, for example, is true and is false, then is true whenever is true, which occurs with probability 0.1.
This conditional distribution can be represented as a program:
if go_out:
if rain:
wet := flip(0.8)
else:
wet := flip(0.1)
else:
if full:
wet := flip(0.6)
else:
wet := flip(0.3)
flip(x) = (random() < x)
where random() returns a random number uniformly in the range [0,1), so flip(x) makes a new independent random variable that is true
with probability x. The logical formula gave these random
variables names.
Logical formulas allow for much more complicated expressions than presented here. Probabilistic programming allows for the full expressivity of the underlying programming language to express probabilistic models. Typically a single program is used to represent the distribution of all variables, rather than having a separate program for each conditional probability.
Noisy-or
There are many cases where something is true if there is something that makes it true. For example, someone has a symptom if there is a disease that causes that symptom; each of the causes can be probabilistic. In natural language understanding, topics may have words probabilistically associated with them; a word is used if there is a topic that makes that word appear. Each of these examples follows the same pattern, called a noisy-or.
In a noisy-or model of a conditional probability, the child is true if one of the parents is activated and each parent has a probability of activation. So the child is an “or” of the activations of the parents.
If has Boolean parents , the noisy-or model of probability is defined by parameters . is defined in terms of a deterministic system with noisy inputs, where
The are unconditionally independent noise variables, with , and means .
The same distribution for can be defined using Boolean variables , where for each , has as its only parent. See Figure 9.8.

and . The variable has . The variables are the parents of . The conditional probability for , , is 1 if any of the are true and 0 if all of the are false. Thus, is the probability of when all of are false; the probability of increases as more of the become true.
Example 9.20.
Suppose the robot could get wet from rain or coffee. There is a probability that it gets wet from rain if it rains, and a probability that it gets wet from coffee if it has coffee, and a probability that it gets wet for other reasons. The robot gets wet if it gets wet from one of the reasons, giving the “or”. You could have , , and, for the bias term, . The robot is wet if it is wet from rain, wet from coffee, or wet for other reasons.
Log-linear Models and Logistic Regression
In a log-linear model unnormalized probabilities are specified using a product of terms, and probabilities are inferred by normalization. When the terms being multiplied are all positive, a product can be represented as the exponential of a sum. A sum of terms is often a convenient term to work with.
The simplest case is for a Boolean variable. To represent conditional probabilities of a Boolean variable :
-
•
The sigmoid function, , plotted in Figure 7.11, has been used previously in this book for logistic regression and neural networks.
-
•
The conditional odds (as often used by bookmakers in gambling)
Decomposing into , and analogously for the numerator, gives
where is the prior odds and is the likelihood ratio. When is a product of terms, the log is a sum of terms.
The logistic regression model of a conditional probability is of the form
| (9.3) |
Assume a dummy input which is always 1; is the bias. This corresponds to a decomposition of the conditional probability, where the likelihood ratio is a product of terms, one for each .
Note that . Thus, determines the probability when all of the parents are zero. Each specifies a value that should be added as changes. . The logistic regression model makes the independence assumption that the influence of each parent on the child does not depend on the other parents. In particular, it assumes that the odds can be decomposed into a product of terms that each only depend on a single variable. When learning logistic regression models (Section 7.3.2), the training data does not need to obey that independence, but rather the algorithm tries to find a logistic regression model that best predicts the training data (in the sense of having the lowest squared error or log loss).
Example 9.21.
Suppose the probability of given whether there is rain, coffee, kids, or whether the robot has a coat, , is
This implies the following conditional probabilities:
This requires fewer parameters than the parameters required for a tabular representation, but makes more independence assumptions.
Noisy-or and logistic regression models are similar, but different. Noisy-or is typically used when the causal assumption that a variable is true if it is caused to be true by one of the parents, is appropriate. Logistic regression is used when the various parents add up to influence the child. See the box.
Noisy-or Compared to Logistic Regression
Noisy-or and logistic regression when used for Boolean parents are similar in many ways. They both take a parameter for each parent plus another parameter that is used when all parents are false. Logistic regression cannot represent zero probabilities. Noisy-or cannot represent cases where a parent being true makes the child less probable (although the negation can be a parent).
They can both represent the probability exactly when zero or one parent is true (as long as there are no zero probabilities for logistic regression). They are quite different in how they handle cases when multiple parents are true.
To see the difference, consider representing , using parameters . Assume the following probabilities when zero or one parent is true:
For noisy-or, . . Solving for gives .
For logistic regression, and .
The predictions for for the other assignments to s are:
Logistic regression is much more extreme than noisy-or when multiple are true. With noisy-or, each probabilistically forces to be true. With logistic regression, each provides independent evidence for .
If the probability is increased, to say, 0.05, with fixed, the probability of given assignments with multiple true for noisy-or goes up (as there are more ways could be true) and for logistic regression goes down (as each true provides less evidence of exceptionality).
One way to extend logistic regression to be able to represent more conditional probabilities is to allow weights for conjunctions of Boolean properties. For example, if Boolean has Booleans and as parents, four weights can be used to define the conditional distribution:
where is 1 only when both and are true – the product of variables with domain corresponds to conjunction. . . . . where the logit function is the inverse of the sigmoid.
In general, for there are parameters, one for each subset of being conjoined (or multiplied). This is known as the canonical representation for Boolean conditional probabilities. It has the same number of parameters as a conditional probability table. It can be made simpler by not representing the zero weights. Logistic regression is the extreme form where all of the interaction (product) weights are zero. It is common to start with the logistic regression form and add as few interaction terms as needed. This is the representaion of conditioning probabilities for Boolean outputs learned by gradient-boosted trees, with the decision-tree paths representing conjunctions.
A logistic regression model for Boolean variables can be represented using weighted logical formulas, where a weighted logical formula is a pair of a formula and a weight, such that is proportional to the exponential of the sum of the weights for the formulas for which is true, and the have their given value. The model of Equation 9.3 can be specified by and for each , where means . For the canonical representation, more complicated formulas can be used; for example, the case in the previous paragraph is represented by adding the weighted formula to the logistic regression weighted formulas.
The extension of logistic regression to non-binary discrete variables is softmax regression; the softmax of linear functions.
Directed and Undirected Graphical Models
A belief network is a directed model; all of the arcs are directed. The model is defined in terms of conditional probabilities.
An alternative is an undirected model. A factor graph consists of a set of variables and a set of nonnegative factors, each with scope a subset of the variables. There is an arc between each variable and the factors it is in the scope of, similar to a constraint network. It is sometimes written as a Markov random field or Markov network where the factors are implicit: the nodes are the variables, with an edge between any pair of nodes if there is a factor containing both.
The joint probability is defined by
where is the tuple of variables in factor and is the tuple of corresponding values.
The constant of proportionality,
is called the partition function. The exact algorithms of Section 9.5 can be used to compute the partition function; those algorithms just assume a set of factors.
Sometimes the factors are defined in terms of weights, so that . This changes the product above to
giving a log-linear model, which is useful for learning as the derivative is simpler and the nonnegative constraint happens automatically, although zero probabilities cannot be represented.
Note that a belief network can also be seen as a factor graph, where the factors are defined in terms of conditional probabilities. The directed and undirected models are collectively called graphical models.
A canonical representation is a representation that has a unique form. One problem with undirected models is that there is no canonical representation for a probability distribution. For example, modifying a factor on by multiplying by a constant and modifying another factor on by dividing by the same constant gives the same model. This means that the model cannot be learned modularly; each factor depends on the others. A belief network forces a particular factorization that gives a canonical representation for a distribution.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.