Artificial
Intelligence 3E
foundations of computational agents
12.3 Sequential Decisions
Generally, agents do not make decisions in the dark without observing something about the world, nor do they make just a single decision. A more typical scenario is that the agent makes an observation, decides on an action, carries out that action, makes observations in the resulting world, then makes another decision conditioned on the observations, and so on. Subsequent actions can depend on what is observed, and what is observed can depend on previous actions. In this scenario, it is often the case that the sole reason for carrying out an action is to provide information for future actions. Actions that are carried out just to acquire information are called information-seeking actions. Such actions are only ever needed in partially observable environments. The formalism does not need to distinguish information-seeking actions from other actions. Typically actions will have both information outcomes as well as effects on the world.
A sequential decision problem models
-
•
what actions are available to the agent at each stage
-
•
what information is, or will be, available to the agent when it has to act
-
•
the effects of the actions, and
-
•
the desirability of these effects.
Example 12.13.
Consider a simple case of diagnosis where a doctor first chooses some tests and then treats a patient, taking into account the outcome of the tests. The reason the doctor may decide to do a test is so that some information (the test results) will be available at the next stage when treatment may be performed. The test results will be information that is available when the treatment is decided, but not when the test is decided. It is often a good idea to test, even if testing itself may harm the patient.
The actions available are the possible tests and the possible treatments. When the test decision is made, the information available will be the symptoms exhibited by the patient. When the treatment decision is made, the information available will be the patient’s symptoms, what tests were performed, and the test results. The effect of the test is the test result, which depends on what test was performed and what is wrong with the patient. The effect of the treatment is some function of the treatment and what is wrong with the patient. The utility may include, for example, costs of tests and treatments, the pain and inconvenience to the patient in the short term, and the long-term prognosis.
12.3.1 Decision Networks
A decision network (also called an influence diagram) is a graphical representation of a finite sequential decision problem. Decision networks extend belief networks to include decision variables and utility. A decision network extends the single-stage decision network to allow for sequential decisions, and allows both chance nodes and decision nodes to be parents of decision nodes.
In particular, a decision network is a directed acyclic graph (DAG) with chance nodes (drawn as ovals), decision nodes (drawn as rectangles), and a utility node (drawn as a diamond). The meaning of the arcs is as follows.
-
•
Arcs coming into decision nodes represent the information that will be available when the decision is made.
-
•
Arcs coming into chance nodes represent probabilistic dependence.
-
•
Arcs coming into the utility node represent what the utility depends on.
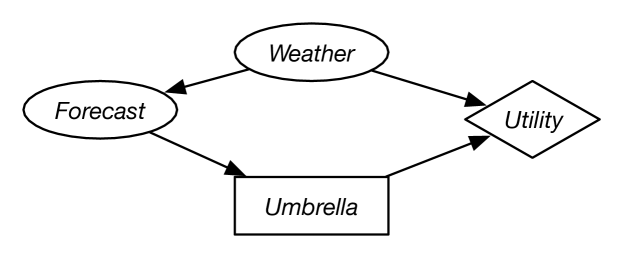
Example 12.14.
Figure 12.9 shows a simple decision network for a decision of whether the agent should take an umbrella when it goes out. The agent’s utility depends on the weather and whether it takes an umbrella. The agent does not get to observe the weather; it only observes the forecast. The forecast probabilistically depends on the weather.
As part of this network, the designer must specify the domain for each random variable and the domain for each decision variable. Suppose the random variable has domain , the random variable has domain , and the decision variable has domain . There is no domain associated with the utility node. The designer also must specify the probability of the random variables given their parents. Suppose is defined by
is given by
| Probability | ||
|---|---|---|
| 0.7 | ||
| 0.2 | ||
| 0.1 | ||
| 0.15 | ||
| 0.25 | ||
| 0.6 |
Suppose the utility function, , is
| 20 | ||
| 100 | ||
| 70 | ||
| 0 |
There is no table specified for the decision variable. It is the task of the planner to determine which value of to select, as a function of the forecast.

Example 12.15.
Figure 12.10 shows a decision network that represents the idealized diagnosis scenario of Example 12.13. The symptoms depend on the disease. What test to perform is decided based on the symptoms. The test result depends on the disease and the test performed. The treatment decision is based on the symptoms, the test performed, and the test result. The outcome depends on the disease and the treatment. The utility depends on the costs of the test and on the outcome.
The outcome does not depend on the test, but only on the disease and the treatment, so the test presumably does not have side-effects. The treatment does not directly affect the utility; any cost of the treatment can be incorporated into the outcome. The utility needs to depend on the test unless all tests cost the same amount.
The diagnostic assistant that is deciding on the tests and the treatments never actually finds out what disease the patient has, unless the test result is definitive, which it, typically, is not.
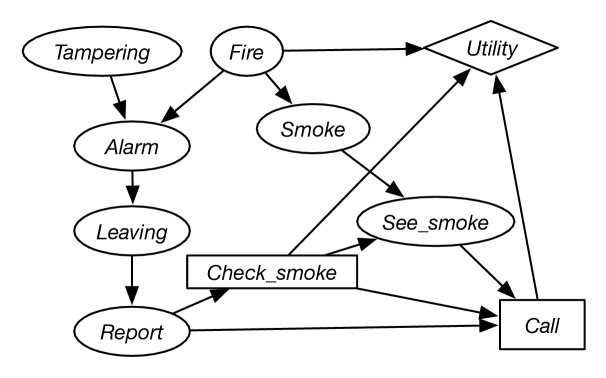
Example 12.16.
Figure 12.11 gives a decision network that is an extension of the belief network of Figure 9.3. The agent can receive a report of people leaving a building and has to decide whether or not to call the fire department. Before calling, the agent can check for smoke, but this has some cost associated with it. The utility depends on whether it calls, whether there is a fire, and the cost associated with checking for smoke.
In this sequential decision problem, there are two decisions to be made. First, the agent must decide whether to check for smoke. The information that will be available when it makes this decision is whether there is a report of people leaving the building. Second, the agent must decide whether or not to call the fire department. When making this decision, the agent will know whether there was a report, whether it checked for smoke, and whether it can see smoke. Assume that all of the variables are binary.
The information necessary for the decision network includes the conditional probabilities of the belief network and
-
•
– how seeing smoke depends on whether the agent looks for smoke and whether there is smoke. Assume that the agent has a perfect sensor for smoke. It will see smoke if and only if it looks for smoke and there is smoke. See Exercise 12.9.
-
•
– how the utility depends on whether the agent checks for smoke, whether there is a fire, and whether the fire department is called. Figure 12.12 provides this utility information.
Figure 12.12: Utility for fire alarm decision network This utility function expresses the cost structure that calling has a cost of 200, checking has a cost of 20, but not calling when there is a fire has a cost of 5000. The utility is the negative of the cost.
A no-forgetting agent is an agent whose decisions are totally ordered in time, and the agent remembers its previous decisions and any information that was available to a previous decision.
A no-forgetting decision network is a decision network in which the decision nodes are totally ordered and, if decision node is before in the total ordering, then is a parent of , and any parent of is also a parent of .
Thus, any information available to is available to any subsequent decision, and the action chosen for decision is part of the information available for subsequent decisions. The no-forgetting condition is sufficient to make sure that the following definitions make sense and that the following algorithms work.
12.3.2 Policies
A policy specifies what the agent should do under all contingencies. A policy consists of a decision function for each decision variable. A decision function for a decision variable is a function that specifies a value for the decision variable for each assignment of values to its parents. Thus, a policy specifies, for each decision variable, what the agent will do for each of the possible observations.
Example 12.17.
In Example 12.14, some of the policies are:
-
•
Always bring the umbrella.
-
•
Bring the umbrella only if the forecast is “rainy.”
-
•
Bring the umbrella only if the forecast is “sunny.”
There are eight different policies, because there are three possible forecasts and there are two choices for each forecast.
Example 12.18.
In Example 12.16, a policy specifies a decision function for and a decision function for . Some of the policies are:
-
•
Never check for smoke, and call only if there is a report.
-
•
Always check for smoke, and call only if it sees smoke.
-
•
Check for smoke if there is a report, and call only if there is a report and it sees smoke.
-
•
Check for smoke if there is no report, and call when it does not see smoke.
-
•
Always check for smoke and never call.
There are four decision functions for . There are decision functions for ; for each of the eight assignments of values to the parents of , the agent can choose to call or not. Thus there are different policies.
Expected Utility of a Policy
Each policy has an expected utility for an agent that follows the policy. A rational agent should adopt the policy that maximizes its expected utility.
A possible world specifies a value for each random variable and each decision variable. A possible world satisfies policy if for every decision variable , has the value specified by the policy given the values of the parents of in the possible world.
A possible world corresponds to a complete history and specifies the values of all random and decision variables, including all observed variables. Possible world satisfies policy if is one possible unfolding of history given that the agent follows policy .
The expected utility of policy is
where , the probability of world , is the product of the probabilities of the values of the chance nodes given their parents’ values in , and is the value of the utility in world .
Example 12.19.
Consider Example 12.14, let be the policy to take the umbrella if the forecast is cloudy and to leave it at home otherwise. The worlds that satisfy this policy are:
Notice how the value for the decision variable is the one chosen by the policy. It only depends on the forecast.
The expected utility of this policy is obtained by averaging the utility over the worlds that satisfy this policy:
where means , means , and similarly for the other values.
An optimal policy is a policy such that for all policies . That is, an optimal policy is a policy whose expected utility is maximal over all policies.
Suppose a binary decision node has binary parents. There are different assignments of values to the parents and, consequently, there are different possible decision functions for this decision node. The number of policies is the product of the number of decision functions for each of the decision variables. Even small examples can have a huge number of policies. An algorithm that simply enumerates the policies looking for the best one will be very inefficient.
12.3.3 Optimizing Decision Networks using Search
The recursive conditioning algorithm for belief networks can be extended to decision networks as follows:
-
•
It takes a context, a set of factors for the conditional distributions of the random variables and the utility, and a set of decision variables.
-
•
It returns a value for the optimal policy given the context and optimal decision functions for the decision variables for that context. The decision functions are represented as a set of pairs, which means the optimal decision has decision variable taking value in .
-
•
The splitting order has the parents of each decision node come before the node, and these are the only nodes before the decision node. In particular, it cannot select a variable to split on that is not a parent of all remaining decision nodes. Thus, it is only applicable to no-forgetting decision networks. If it were to split on a variable that is not a parent of a decision variable , it can make a different choice of a value for depending on the value of , which cannot be implemented by an agent that does not know the value of when it has to do .
-
•
The utility node does not need to be treated differently from the factors defining probabilities; the utility just provides a number that is multiplied by the probabilities.
-
•
To split on a decision node, the algorithm chooses a value that maximizes the values returned for each assignment of a value for that node.
Figure 12.13 extends the naive search algorithm of Figure 9.9 to solve decision networks. It is easiest to think of this algorithm as computing a sum over products, choosing the maximum value when there is a choice. The value returned by the recursive call is a mix of the probability and utility.
Example 12.20.
Consider Example 12.16. The algorithm first splits on as it is a parent of all decision nodes. Consider the branch. It then calls with context , and the decision variable is split. The recursive call will determine whether it is better to check when the report is false. It then splits on and then . The other factors can be eliminated in any order.
The call to with context returns the pair
where is the optimal policy when .
Table 12.1 shows what factors can be evaluated for one variable ordering.
| Variable | Factor(s) Evaluated |
|---|---|
| – | |
| – | |
| – | |
| – | |
| , | |
| , | |
| , |
It is difficult to interpret the numbers being returned by the recursive calls. Some are just products of probability (recursive calls after the factor is evaluated), and some are a mix of probability and utility. The easiest way to think about this is that the algorithm is computing the sum of a product of numbers, maximizing for a choice at the decision nodes.
The algorithm of Figure 12.13 does not exploit the independence of graphical structure, but all of the enhancements of recursive conditioning, namely recognizing disconnected components and judicious caching can be incorporated unchanged.
12.3.4 Variable Elimination for Decision Networks
Variable elimination can be adapted to find an optimal policy. The idea is first to consider the last decision, find an optimal decision for each value of its parents, and produce a factor of these maximum values. This results in a new decision network, with one less decision, that can be solved recursively.
Figure 12.14 shows how to use variable elimination for decision networks. Essentially, it computes the expected utility of an optimal decision. It eliminates the random variables that are not parents of a decision node by summing them out according to some elimination ordering. The ordering of the random variables being eliminated does not affect correctness and so it can be chosen for efficiency.
After eliminating all of the random variables that are not parents of a decision node, in a no-forgetting decision network, there must be one decision variable that is in a factor where all of the variables, other than , in are parents of . This decision is the last decision in the ordering of decisions.
To eliminate that decision node, chooses the values for the decision that result in the maximum utility. This maximization creates a new factor on the remaining variables and a decision function for the decision variable being eliminated. This decision function created by maximizing is one of the decision functions in an optimal policy.
Example 12.21.
In Example 12.14, there are three initial factors representing , , and . First, it eliminates by multiplying all three factors and summing out , giving a factor on and , shown on left of Table 12.2.
| Value | ||
|---|---|---|
| 12.95 | ||
| 49.0 | ||
| 8.05 | ||
| 14.0 | ||
| 14.0 | ||
| 7.0 |
| Value | |
|---|---|
| 49.0 | |
| 14.0 | |
| 14.0 |
To maximize over , for each value of , selects the value of that maximizes the value of the factor. For example, when the forecast is , the agent should leave the umbrella at home for a value of 49.0. The resulting decision function is shown in Table 12.2 (center), and the resulting factor is shown in Table 12.2 (right).
It now sums out from this factor, which gives the value 77.0. This is the expected value of the optimal policy.
Example 12.22.
Consider Example 12.16. The initial factors are shown in Table 12.3.
Initial factors:
The factors that are removed and created for one elimination ordering:
| Variable | How | Removed | Factor Created |
|---|---|---|---|
| sum | , | ||
| sum | , , , | ||
| sum | , | ||
| sum | , | ||
| sum | , | ||
| max | |||
| sum | |||
| max | |||
| sum |
The expected utility is the product of the probability and the utility, as long as the appropriate actions are chosen.
Table 12.3 (bottom) shows the factors that are removed and created for one elimination ordering. The random variables that are not parents of a decision node are summed out first.
The factor is a number that is the expected utility of the optimal policy.
The following gives more detail of one of the factors. After summing out , , , , and , there is a single factor, , part of which (to two decimal places) is
| Value | |||||
|---|---|---|---|---|---|
| 0 | |||||
| 0 | |||||
| … | … | … | … | … |
From this factor, an optimal decision function can be created for by selecting a value for that maximizes for each assignment to , , and .
Consider the case when , , and . The maximum of and is , so for this case, the optimal action is with value . This maximization is repeated for the other values of , , and .
An optimal decision function for is
| … | … | … | … |
The value for when , , and is arbitrary. It does not matter what the agent plans to do in this situation, because the situation never arises. The algorithm does not need to treat this as a special case.
The factor resulting from maximizing contains the maximum values for each combination of , , and :
| Value | |||
|---|---|---|---|
| 0 | |||
| … | … | … | … |
Summing out gives the factor
| Value | ||
|---|---|---|
Maximizing for each value of gives the decision function
and the factor
| Value | |
|---|---|
Summing out gives the expected utility of (taking into account rounding errors).
Thus, the policy returned can be seen as the rules
The last of these rules is never used because the agent following the optimal policy does check for smoke if there is a report. It remains in the policy because has not determined an optimal policy for when it is optimizing .
Note also that, in this case, even though checking for smoke has an immediate negative reward, checking for smoke is worthwhile because the information obtained is valuable.
The following example shows how the factor containing a decision variable can contain a subset of its parents when the VE algorithm optimizes the decision.
Example 12.23.
Consider Example 12.14, but with an extra arc from to . That is, the agent gets to observe both the weather and the forecast. In this case, there are no random variables to sum out, and the factor that contains the decision node and a subset of its parents is the original utility factor. It can then maximize , giving the decision function and the factor:
| 100 | |
| 70 |
Note that the forecast is irrelevant to the decision. Knowing the forecast does not give the agent any useful information. Summing out gives a factor where all of the values are 1.
Summing out , where , gives the expected utility .
Variable elimination for decision networks of Figure 12.14 has similar complexity to the combination of depth-first search of Figure 12.13 with recursive conditioning. They are carrying out the same computations on a different order. In particular, the values stored in the cache of recursive conditioning are the same as the values in the factors of variable elimination. Recursive conditioning allows for the exploitation of various representations of conditional probability, but storing the values in a cache is less efficient than storing the values using a tabular representation. When the networks are infinite, as below, the more sophisticated algorithms are usually based on one or the other.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.