Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
3.11 Exercises
-
1.
Comment on the following quote: “One of the main goals of AI should be to build general heuristics applicable to any graph-searching problem.”
-
2.
Which of the path-finding_ search procedures are fair in the sense that any element on the frontier will eventually be chosen? Consider this question for finite graphs without cycles, finite graphs with cycles, and infinite graphs (with finite branching factors).
-
3.
Consider the problem of finding a path in the grid shown in Figure 3.14 from the position to the position . A piece can move on the grid horizontally or vertically, one square at a time. No step may be made into a forbidden shaded area.
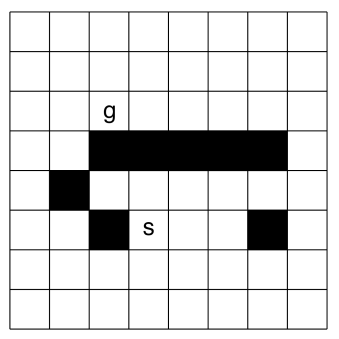
Figure 3.14: A grid-searching problem -
(a)
On the grid shown in Figure 3.14, number the nodes expanded (in order) for a depth-first search from to , given that the order of the operators is up, left, right, and down. Assume there is cycle pruning. What is the first path found?
-
(b)
On a copy of the same grid, number the nodes expanded, in order, for a greedy best-first search from to . Manhattan distance should be used as the evaluation function. The Manhattan distance between two points is the distance in the -direction plus the distance in the -direction. It corresponds to the distance traveled along city streets arranged in a grid. Assume multiple-path pruning. What is the first path found?
-
(c)
On a copy of the same grid, number the nodes expanded, in order, for a heuristic depth-first search from to , given Manhattan distance as the evaluation function. Assume cycle pruning. What is the path found?
-
(d)
Number the nodes in order for an search, with multiple-path pruning, for the same grid. What is the path found?
-
(e)
Show how to solve the same problem using dynamic programming. Give the cost_to_goal value for each node, and show which path is found.
-
(f)
Based on this experience, discuss which algorithms are best suited for this problem.
-
(g)
Suppose that the grid extended infinitely in all directions. That is, there is no boundary, but , , and the blocks are in the same positions relative to each other. Which methods would no longer find a path? Which would be the best method, and why?
-
(a)
-
4.
This question investigates using graph searching to design video presentations. Suppose there exists a database of video segments, together with their length in seconds and the topics covered, set up as follows:
Segment Length Topics covered seg0 10 [welcome] seg1 30 [skiing, views] seg2 50 [welcome, artificial_intelligence, robots] seg3 40 [graphics, dragons] seg4 50 [skiing, robots] Represent a node as a pair:
where is a list of segments that must be in the presentation, and is a list of topics that also must be covered. Assume that none of the segments in cover any of the topics in .
The neighbors of a node are obtained by first selecting a topic from . There is a neighbor for each segment that covers the selected topic. [Part of this exercise is to think about the exact structure of these neighbors.]
For example, given the aforementioned database of segments, the neighbors of the node , assuming that was selected, are and .
Thus, each arc adds exactly one segment but can cover one or more topics. Suppose that the cost of the arc is equal to the time of the segment added.
The goal is to design a presentation that covers all of the topics in . The starting node is , and the goal nodes are of the form . The cost of the path from a start node to a goal node is the time of the presentation. Thus, an optimal presentation is a shortest presentation that covers all of the topics in .
-
(a)
Suppose that the goal is to cover the topics and the algorithm always select the leftmost topic to find the neighbors for each node. Draw the search space expanded for a lowest-cost-first search until the first solution is found. This should show all nodes expanded, which node is a goal node, and the frontier when the goal was found.
-
(b)
Give a non-trivial heuristic function that is admissible. [Note that for all is the trivial heuristic function.] Does it satisfy the monotone restriction for a heuristic function?
-
(a)
-
5.
Draw two different graphs, indicating start and goal nodes, for which forward search is better in one and backward search is better in the other.
-
6.
The algorithm does not define what happens when multiple elements on the frontier have the same -value. Compare the following tie-breaking conventions by first conjecturing which will work better, and then testing it on some examples. Try it on some examples where there are multiple optimal paths to a goal (such as finding a path from one corner of a rectangular grid to the far corner of a grid). Of the paths on the frontier with the same minimum -value, select one:
-
(a)
uniformly at random
-
(b)
that has been on the frontier the longest
-
(c)
that was most recently added to the frontier.
-
(d)
with the smallest -value
-
(e)
with the least cost
The last two may require other tie-breaking conventions when the cost and values are equal.
-
(a)
-
7.
What happens if the heuristic function is not admissible, but is still nonnegative? What can we say about the path found by if the heuristic function
-
(a)
is less than times the least-cost path (e.g., is less than greater than the cost of the least-cost path)
-
(b)
is less than more than the least-cost path (e.g., is less than 10 units plus the cost of the optimal path)?
Develop a hypothesis about what would happen and show it empirically or prove your hypothesis. Does it change if multiple-path pruning is in effect or not?
Does loosening the heuristic in either of these ways improve efficiency? Try search where the heuristic is multiplied by a factor , or where a cost is added to the heuristic, for a number of graphs. Compare these on the time taken (or the number of nodes expanded) and the cost of the solution found for a number of values of or .
-
(a)
-
8.
How can depth-first branch-and-bound be modified to find a path with a cost that is not more than, say, greater than the least-cost path. How does this algorithm compare to from the previous question?
-
9.
The overhead for iterative deepening with on the denominator is not a good approximation when . Give a better estimate of the complexity of iterative deepening when . (Hint: think about the case when .) How does this compare with for such graphs? Suggest a way that iterative deepening can have a lower overhead when the branching factor is close to 1.
-
10.
Bidirectional search must be able to determine when the frontiers intersect. For each of the following pairs of searches specify how to determine when the frontiers intersect.
-
(a)
Breadth-first search and depth-bounded depth-first search.
-
(b)
Iterative deepening search and depth-bounded depth-first search.
-
(c)
and depth-bounded depth-first search.
-
(d)
and .
-
(a)
-
11.
Consider the algorithm sketched in the counterexample of the box.
-
(a)
When can the algorithm stop? (Hint: it does not have to wait until the forward search finds a path to a goal.)
-
(b)
What data structures should be kept?
-
(c)
Specify the algorithm in full.
-
(d)
Show that it finds the optimal path.
-
(e)
Give an example where it expands (many) fewer nodes than .
-
(a)
-
12.
Give a statement of the optimality of that specifies a class of algorithms for which is optimal. Give the formal proof.
-
13.
The depth-first branch-and-bound of Figure 3.12 is like a depth-bounded search in that it only finds a solution if there is a solution with cost less than bound. Show how this can be combined with an iterative deepening search to increase the depth bound if there is no solution for a particular depth bound. This algorithm must return in a finite graph if there is no solution. The algorithm should allow the bound to be incremented by an arbitrary amount and still return an optimal (least-cost) solution when there is a solution.