Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
9.2.1 Single-Stage Decision Networks
A decision tree is a state-based representation where each path from a root to a leaf corresponds to a state. It is, however, often more natural and more efficient to represent and reason directly in terms of features, represented as variables.
A single-stage decision network is an extension of a belief network with three kinds of nodes:
-
•
Decision nodes, drawn as rectangles, represent decision variables. The agent gets to choose a value for each decision variable. Where there are multiple decision variables, we assume there is a total ordering of the decision nodes, and the decision nodes before a decision node in the total ordering are the parents of .
-
•
Chance nodes, drawn as ovals, represent random variables. These are the same as the nodes in a belief network. Each chance node has an associated domain and a conditional probability of the variable, given its parents. As in a belief network, the parents of a chance node represent conditional dependence: a variable is independent of its non-descendants, given its parents. In a decision network, both chance nodes and decision nodes can be parents of a chance node.
-
•
A utility node, drawn as a diamond, represents the utility. The parents of the utility node are the variables on which the utility depends. Both chance nodes and decision nodes can be parents of the utility node.
Each chance variable and each decision variable has a domain. There is no domain for the utility node. Whereas the chance nodes represent random variables and the decision nodes represent decision variables, there is no utility variable.
Associated with a decision network is a conditional probability for each chance node given its parents (as in a belief network) and a utility as a function of the utility node’s parents. In the specification of the network, there are no functions associated with a decision (although the algorithm will construct a function).
| Value | ||
|---|---|---|
| 0.2 | ||
| 0.8 | ||
| 0.01 | ||
| 0.99 |
| Utility | |||
|---|---|---|---|
| 35 | |||
| 95 | |||
| 30 | |||
| 75 | |||
| 3 | |||
| 100 | |||
| 0 | |||
| 80 |
Example 9.10.
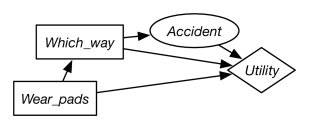
Figure 9.7 gives a decision network representation of Example 9.6. There are two decisions to be made: which way to go and whether to wear padding. Whether the agent has an accident only depends on which way they go. The utility depends on all three variables.
This network requires two factors: a factor representing the conditional probability, , and a factor representing the utility as a function of , , and . Tables for these factors are shown in Figure 9.7.
A policy for a single-stage decision network is an assignment of a value to each decision variable. Each policy has an expected utility. An optimal policy is a policy whose expected utility is maximal. That is, it is a policy such that no other policy has a higher expected utility. The value of a decision network is the expected utility of an optimal policy for the network.
Figure 9.8 shows how variable elimination is used to find an optimal policy in a single-stage decision network. After pruning irrelevant nodes and summing out all random variables, there will be a single factor that represents the expected utility for each combination of decision variables. This factor does not have to be a factor on all of the decision variables; however, those decision variables that are not included are not relevant to the decision.
Example 9.11.
Consider running on the decision network of Figure 9.7. No nodes are able to be pruned, so it sums out the only random variable, . To do this, it multiplies both factors because they both contain , and sums out , giving the following factor:
| Value | ||
|---|---|---|
Thus, the policy with the maximum value – the optimal policy – is to take the short way and wear pads, with an expected utility of 83.