Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
8.6.1 Sampling from a Single Variable
The simplest case is to generate the probability distribution of a single variable. This is the base case the other methods build on.
From Probabilities to Samples
To generate samples from a single discrete or real-valued variable, , first totally order the values in the domain of . For discrete variables, if there is no natural order, just create an arbitrary ordering. Given this ordering, the cumulative probability distribution is a function of , defined by .
To generate a random sample for , select a random number in the domain . We select from a uniform distribution to ensure that each number between 0 and 1 has the same chance of being chosen. Let be the value of that maps to in the cumulative probability distribution. That is, is the element of such that or, equivalently, . Then, is a random sample of , chosen according to the distribution of .
Example 8.39.
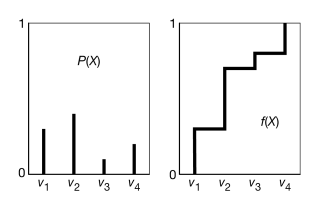
Consider a random variable with domain . Suppose , , , and . First, totally order the values, say . Figure 8.27 shows , the distribution for , and , the cumulative distribution for . Consider value ; 0.3 of the domain of maps back to . Thus, if a sample is uniformly selected from the -axis, has a 0.3 chance of being selected, has a chance of being selected, and so forth.
From Samples to Probabilities
Probabilities can be estimated from a set of samples using the sample average. The sample average of a proposition is the number of samples where is true divided by the total number of samples. The sample average approaches the true probability as the number of samples approaches infinity by the law of large numbers.
Hoeffding’s inequality provides an estimate of the error of the sample average as the probability given samples, with the guarantee of the following proposition.
Proposition 8.6 (Hoeffding).
Suppose is the true probability, and is the sample average from independent samples; then
This theorem can be used to determine how many samples are required to guarantee a probably approximately correct estimate of the probability. To guarantee that the error is always less than some , infinitely many samples are required. However, if you are willing to have an error greater than in of the cases, solve for , which gives
For example, suppose you want an error less than , nineteen times out of twenty; that is, you are only willing to tolerate an error bigger than 0.1 in 5% of the cases. You can use Hoeffding’s bound by setting to and , which gives . Thus, you guarantee such bounds on the error with 185 samples. If you want an error of less than in at least of the cases, 18,445 samples could be used. If you want an error of less than in of the cases, samples could be used.