Artificial
Intelligence 2E
foundations of computational agents
The third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including full text).
14.3 Ontologies and Knowledge Sharing
Building large knowledge-based systems is complex:
-
•
Knowledge often comes from multiple sources and must be integrated. Moreover, these sources may not have the same division of the world. Often knowledge comes from different fields that have their own distinctive terminology and divide the world according to their own needs.
-
•
Systems evolve over time and it is difficult to anticipate all future distinctions that should be made.
-
•
The people involved in designing a knowledge base must choose what individuals and relationships to represent. The world is not divided into individuals; that is something done by intelligent agents to understand the world. Different people involved in a knowledge-based system should agree on this division of the world.
-
•
It is often difficult to remember what your own notation means, let alone to discover what someone else’s notation means. This has two aspects:
-
–
given a symbol used in the computer, determining what it means
-
–
given a concept in someone’s mind, determining what symbol to use. This has three aspects:
-
*
determining whether the concept has already been defined
-
*
if it has been defined, discovering what symbol has been used for it
-
*
if it is not already defined, finding related concepts that it can be defined in terms of.
-
*
-
–
The Semantic Web
The semantic web is a way to allow machine-interpretable knowledge to be distributed on the World Wide Web. Instead of just serving HTML pages that are meant to be read by humans, websites will also provide information that can be used by computers.
At the most basic level, XML (the Extensible Markup Language) provides a syntax designed to be machine readable, but which is also possible for humans to read. It is a text–based language, where items are tagged in a hierarchical manner. The syntax for XML can be quite complicated, but at the simplest level, the scope of a tag is either in the form , or in the form .
A URI (a Uniform Resource Identifier) is used to uniquely identify a resource. A resource is anything that can be uniquely identified, including individuals, classes and properties. Often URIs use the syntax of web addresses.
RDF (the Resource Description Framework) is a language built on XML, for individual–property–value triples.
RDF–S (RDF Schema) lets you define resources (and so also properties) in terms of other resources (e.g., using , and ). RDF–S also lets you restrict the domain and range of properties and provides containers: sets, sequences, and alternatives.
RDF allows sentences in its own language to be reified. This means that it can represent arbitrary logical formulas and so is not decidable in general. Undecidability is not necessarily a bad thing; it just means that you cannot put a bound on the time a computation may take. Logic programs with function symbols and programs in virtually all programming languages are undecidable.
OWL (the Web Ontology Language) is an ontology language for the World Wide Web. It defines some classes and properties with a fixed interpretation that can be used for describing classes, properties, and individuals. It has built-in mechanisms for equality of individuals, classes, and properties, in addition to restricting domains and ranges of properties and other restrictions on properties (e.g., transitivity, cardinality).
There have been some efforts to build large universal ontologies, such as Cyc (www.cyc.com), but the idea of the semantic web is to allow communities to converge on ontologies. Anyone can build an ontology. People who want to develop a knowledge base can use an existing ontology or develop their own ontology, usually building on existing ontologies. Because it is in their interest to have semantic interoperability, companies and individuals should tend to converge on standard ontologies for their domain or to develop mappings from their ontologies to others’ ontologies.
To share and communicate knowledge, it is important to be able to develop a common vocabulary and an agreed-on meaning for that vocabulary.
A conceptualization is a mapping between symbols used in the computer, the vocabulary, and the individuals and relations in the world. It provides a particular abstraction of the world and notation for that abstraction. A conceptualization for small knowledge bases can be in the head of the designer or specified in natural language in the documentation. This informal specification of a conceptualization does not scale to larger systems where the conceptualization must be shared.
In philosophy, ontology is the study of what exists. In AI, an ontology is a specification of the meanings of the symbols in an information system. That is, it is a specification of a conceptualization. It is a specification of what individuals and relationships are assumed to exist and what terminology is used for them. Typically, it specifies what types of individuals will be modeled, specifies what properties will be used, and gives some axioms that restrict the use of that vocabulary.
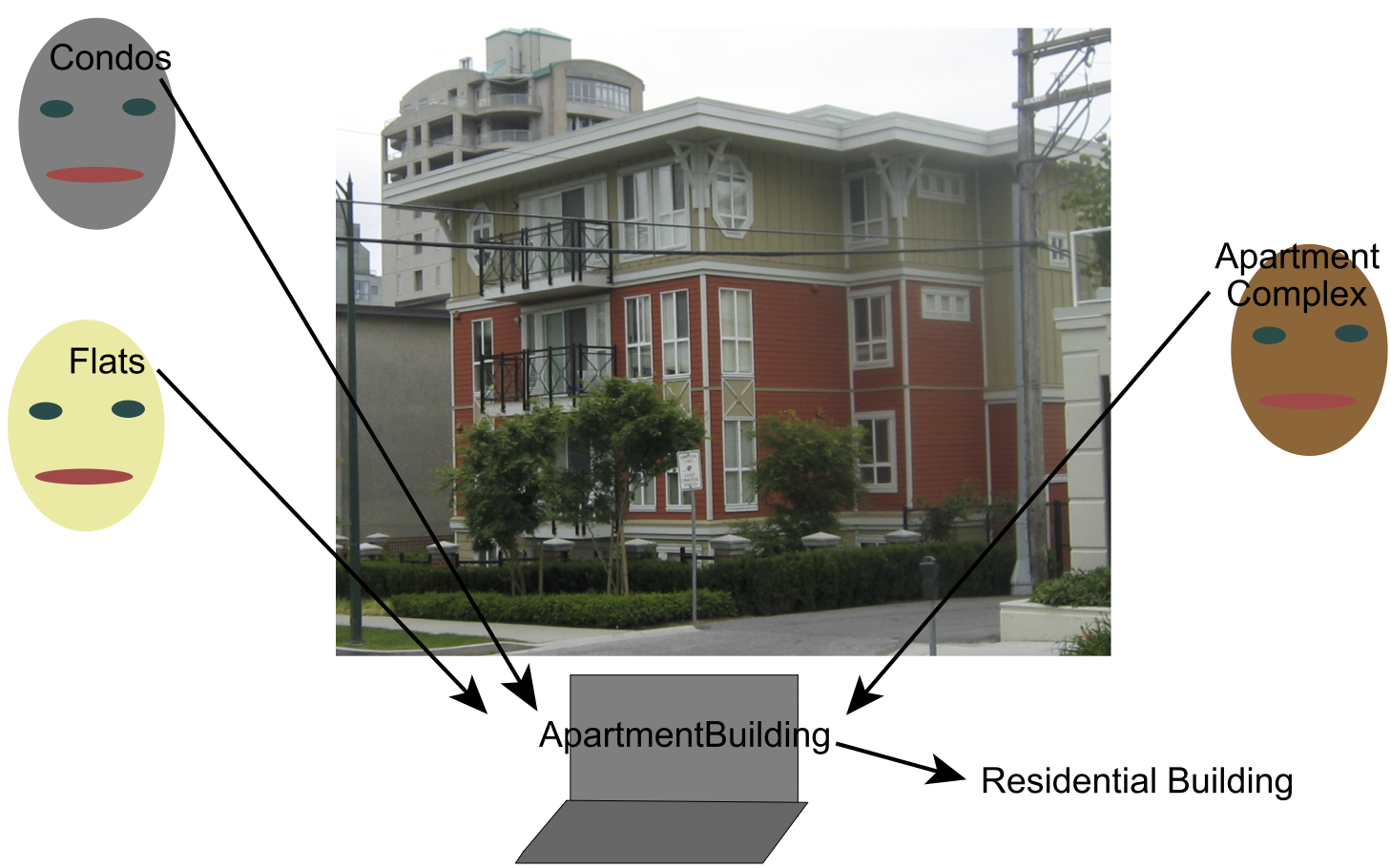
Example 14.10.
An ontology of individuals that could appear on a map could specify that the symbol “ApartmentBuilding” will represent apartment buildings. The ontology will not define an apartment building, but it will describe it well enough so that others can understand the definition. We want other people, who who may call such buildings “Condos”, “Flats” or “Apartment Complex” to be able to find the appropriate symbol in the ontology (see Figure 14.3). That is, given a concept, people want to be able to find the symbol, and, given the symbol, they want to be able to determine what it means.
An ontology may give axioms to restrict the use of some symbols. For example, it may specify that apartment buildings are buildings, which are human-constructed artifacts. It may give some restriction on the size of buildings so that shoeboxes cannot be buildings or that cities cannot be buildings. It may state that a building cannot be at two geographically dispersed locations at the same time (so if you take off some part of the building and move it to a different location, it is no longer a single building). Because apartment buildings are buildings, these restrictions also apply to apartment buildings.
Ontologies are usually written independently of a particular application and often involve a community agreeing on the meanings of symbols. An ontology consists of
-
•
a vocabulary of the categories of the things (both classes and properties) that a knowledge base may want to represent
-
•
an organization of the categories, for example into an inheritance hierarchy using or , or using Aristotelian definitions, and
-
•
a set of axioms restricting the definition of some of the symbols to better reflect their intended meaning – for example, that some property is transitive, or that the domain and range are restricted, or restrictions on the number of values a property can take for each individual. Sometimes relationships are defined in terms of more primitive relationships but, ultimately, the relationships are grounded out into primitive relationships that are not actually defined.
Aristotelian Definitions
Categorizing objects, the basis for modern ontologies, has a long history. Aristotle [350 B.C.E.] suggested the definition of a class in terms of
-
•
Genus: a superclass of . The plural of genus is genera.
-
•
Differentia: the attributes that make members of the class different from other members of the superclass of .
He anticipated many of the issues that arise in definitions:
If genera are different and co-ordinate, their differentiae are themselves different in kind. Take as an instance the genus “animal” and the genus “knowledge”. “With feet”, “two-footed”, “winged”, “aquatic”, are differentiae of “animal”; the species of knowledge are not distinguished by the same differentiae. One species of knowledge does not differ from another in being “two-footed”. [Aristotle, 350 B.C.E.]
Note that “co-ordinate” here means neither is subordinate to the other.
In the style of modern ontologies, we would say that “animal” is a class, and “knowledge” is a class. The property “two-footed” has domain “animal”. If something is an instance of knowledge, it does not have a value for the property “two-footed”.
To build an ontology based on Aristotelian definitions:
-
•
For each class you may want to define, determine a relevant superclass, and then select those attributes that distinguish the class from other subclasses. Each attribute gives a property and a value.
-
•
For each property, define the most general class for which it makes sense, and define the domain of the property to be this class. Make the range another class that makes sense (perhaps requiring this range class to be defined, either by enumerating its values or by defining it using an Aristotelian definition).
This can get quite complicated. For example, to define “luxury furniture”, the superclass could be “furniture” and the distinguishing characteristics are cost is high and it feels soft. The softness of furniture is different than the softness of rocks. You also probably want to distinguish the squishiness from the texture (both of which may be regarded as soft).
The class hierarchy is an acyclic directed graph (DAG), forming a lattice. This methodology does not, in general, give a tree hierarchy of classes. Objects can be in many classes. Each class does not have a single most-specific superclass. However, it is still straightforward to check whether one class is a subclass of another, to check the meaning of a class, and to determine the class that corresponds to a concept in a person’s head.
In rare cases, the natural class hierarchy forms a strict tree, most famously in the Linnaean taxonomy of living things. The reason this is a tree is because of evolution. Trying to force a tree structure in other domains has been much less successful.
An ontology does not specify the individuals not known at design time. For example, an ontology of buildings would typically not include actual buildings. An ontology would specify those individuals that are fixed and should be shared, such as the days of the week, or colors.
Example 14.11.
Consider a trading agent that is designed to find accommodations. Users could use such an agent to describe what accommodation they want. The trading agent could search multiple knowledge bases to find suitable accommodations or to notify users when some appropriate accommodation becomes available. An ontology is required to specify the meaning of the symbols for the user and to allow the knowledge bases to interoperate. It provides the semantic glue to tie together the users’ needs with the knowledge bases.
In such a domain, houses and apartment buildings may both be residential buildings. Although it may be sensible to suggest renting a house or an apartment in an apartment building, it may not be sensible to suggest renting an apartment building to someone who does not actually specify that they want to rent the whole building. A “living unit” could be defined to be the collection of rooms that some people, who are living together, live in. A living unit may be what a rental agency offers to rent. At some stage, the designer may have to decide whether a room for rent in a house is a living unit, or even whether part of a shared room that is rented separately is a living unit. Often the boundary cases – cases that may not be initially anticipated – are not clearly delineated but become better defined as the ontology evolves.
The ontology would not contain descriptions of actual houses or apartments because, at the time the ontology is defined, the designers will not know what houses will be described by the ontology. The ontology will change much slower than actual available accommodation.
The primary purpose of an ontology is to document what the symbols mean – the mapping between symbols (in a computer) and concepts (in someone’s head). Given a symbol, a person is able to use the ontology to determine what it means. When someone has a concept to be represented, the ontology is used to find the appropriate symbol or to determine that the concept does not exist in the ontology. The secondary purpose, achieved by the use of axioms, is to allow inference or to determine that some combination of values is inconsistent. The main challenge in building an ontology is the organization of the concepts to allow a human to map concepts into symbols in the computer, and for the computer to infer useful new knowledge from stated facts.