Artificial
Intelligence 3E
foundations of computational agents
11.3 Inferring Causality
You cannot determine the effect of intervention from observational data. However, you can infer causality if you are prepared to make assumptions. A problem with inferring causality is that there can be confounders, other variables correlated with the variables of interest. A confounder between and is a variable such that and . A confounder can account for the correlation between and by being a common cause of both.
Example 11.7.
Consider the effect of a drug on a disease. The effect of the drug cannot be determined by considering the correlation between taking the drug and the outcome. The reason is that the drug and the outcome can be correlated for other reasons than just the effect of the drug. For example, the severity of a disease and the gender of the patient may be correlated with both, and so potential confounders. If the drug is only given to the sickest people, the drug may be positively correlated with a poor outcome, even though the drug might work very well – it makes each patient less sick than they would have been if they were not given the drug.
The story of how the variables interact could be represented by the network of Figure 11.7. In this figure, the variable could represent whether the patient was given the drug or not. Whether a patient is given a drug depends on the severity of the disease (variable ) and the gender of the person (variable ). You might not be sure whether is a confounder, but because there is a possibility, it can be included to be safe.
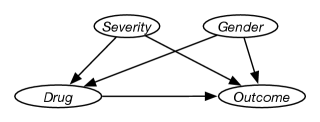
From observational data, can be determined, but to determine whether a drug is useful requires , which is potentially different because of the confounders. The important part of the network of Figure 11.7 are the missing nodes and arcs; this assumes that there are no other confounders.
In a randomized controlled trial one variable (e.g., a drug) is given to patients at random, selected using a random number generator, independently of its parents (e.g., independently of how severe the disease is). In a causal network, this is modeled by removing the arcs into that variable, as it is assumed that the random number generator is not correlated with other variables. This then allows us to determine the effect of making the variable true with all confounders removed.
11.3.1 Backdoor Criterion
If one is prepared to commit to a model, in particular to identify all possible confounders, it is possible to determine causal knowledge from observational data. This is appropriate when you identify all confounders and enough of them are observable.
Example 11.8.
In Example 11.7, there are three reasons why the drug and outcome are correlated. One is the direct effect of the drug on the outcome. The others are due to the confounders of the severity of the disease and the gender of the patient. The aim to measure the direct effect. If the severity and gender are the only confounders, you can adjust for them by considering the effect of the drug on the outcome for each severity and gender separately, and weighting the outcome appropriately:
The last step follows because are all the parents of , for which, because of the assumption of a causal network, observing and doing have the same effect. These can all be judged without acting.
This analysis relies on the assumptions that severity and gender are the only confounders and both are observable.
The previous example is a specific instance of the backdoor criterion. A set of variables satisfies the backdoor criterion for and with respect to directed acyclic graph if
-
•
can be observed
-
•
no node in is a descendant of , and
-
•
blocks every path between and that contains an arrow into .
If satisfies the backdoor criterion, then
The aim is to find an observable set of variables which blocks all spurious paths from to , leaves all directed paths from to , and doesn’t create any new spurious paths. If is observable, the above formula can be estimated from observational data.
It is often challenging, or even impossible, to find a that is observable. For example, even though “drug prone” in Example 11.2 blocks all paths in Figure 11.2, because it cannot be measured, it is not useful.
11.3.2 Do-calculus
The do-calculus tells us how probability expressions involving the do-operator can be simplified. It is defined in terms of the following three rules:
-
•
If blocks all of the paths from to in the graph obtained after removing all of the arcs into :
This rule lets us remove observations from a conditional probability. This is effectively d-separation in the manipulated graph.
-
•
If satisfies the backdoor criterion, for and :
This rule lets us convert an intervention into an observation.
-
•
If there are no directed paths from to , or from to :
This only can be used when there are no observations, and tells us that the only effects of an intervention are on the descendants of the intervened variable.
These three rules are complete in the sense that all cases where interventions can be reduced to observations follow from applications of these rules.
11.3.3 Front-Door Criterion
Sometimes the backdoor criterion is not applicable because the confounding variables are not observable. One case where it is still possible to derive the effect of an action is when there is an intermediate, mediating variable or variables between the intervention variable and the effect, and where the mediating variable is not affected by the confounding variables, given the intervention variable. This case is covered in the front-door criterion.
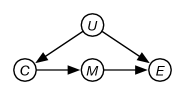
Consider the generic network of Figure 11.8, where the aim is to predict , where the confounders are unobserved and the intermediate mediating variable is independent of given . This pattern can be created by collecting all confounders into , and all mediating variables into , and marginalizing other variables to fit the pattern.
The backdoor criterion is not applicable here, because is not observed. When is observed and is independent of given , the do-calculus can be used to infer the effect on of intervening on .
Let’s first introduce and marginalize it out, as in belief network inference:
| (11.1) | ||||
| (11.2) | ||||
| (11.3) |
Step (11.1) follows using the second rule of the do-calculus because blocks the backdoor between and . Step (11.2) uses the second rule of the do-calculus as satisfies the backdoor criterion between and ; there are no backdoors between and , given nothing is observed. Step (11.3) uses the third rule of the do-calculus as there are no causal paths from to in the graph obtained by removing the arcs into (which is the effect of ).
The intervention on does not affect . This conditional probability can be computed by introducing and marginalizing it from the network of Figure 11.8. The is not intervened on, so let’s give it a new name, :
As closes the backdoor between and , by the second rule, and there are no backdoors between and :
Thus, reduces to observable quantities only:
Thus the intervention on can be inferred from observable data only as long as is observable and the mediating variable is observable and independent of all confounders given .
One of the lessons from this is that it is possible to make causal conclusions from observational data and assumptions on causal mechanisms. Indeed, it is not possible to make causal conclusions without assumptions on causal mechanisms. Even randomized trials require the assumption that the randomizing mechanism is independent of the effects.
11.3.4 Simpson’s Paradox
Simpson’s paradox occurs when considering subpopulations gives different conclusions than considering the population as a whole. This is a case where different conclusions are drawn from the same data, depending on an underlying causal model.
Example 11.9.
Consider the following (fictional) dataset of 1000 students, 500 of whom were using a particular method for learning a concept (the treatment variable ), and whether they were judged to have understood the concept (evaluation ) for two subpopulations (one with and one with ):
| Rate | ||||
|---|---|---|---|---|
| 90 | 10 | |||
| 290 | 110 | |||
| 110 | 290 | |||
| 10 | 90 |
where the integers are counts, and the rate is the proportion that understood (). For example, there were 90 students with , , and , and 10 students with , , and , and so 90% of the students with , have .
For both subpopulations, the understanding rate for those who used the method is better than for those who didn’t use the method. So it looks like the method works.
Combining the subpopulations gives
| Rate | |||
|---|---|---|---|
| 200 | 300 | ||
| 300 | 200 |
where the understanding was better for the students who didn’t use the method.
For making decisions for a student, it isn’t clear whether it is better to determine whether the condition is true of the student, in which case it is better to use the method, or to ignore the condition, in which case it is better not to use the method. The data doesn’t tell us which is the correct answer.
In the previous example, the data does not specify what to do. You need to go beyond the data by building a causal model.
Example 11.10.
In Example 11.9, to make a decision on whether to use the method, consider whether is a cause for or is a cause of . Note that these are not the only two cases; more complicated cases are beyond the scope of this book.
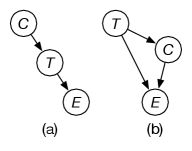
In Figure 11.9(a), is used to select which treatment was chosen (e.g., might be the student’s prior knowledge). In this case, the data for each condition is appropriate, so based on the data of Example 11.9, it is better to use the method.
In Figure 11.9(b), is a consequence of the treatment, such as whether the students learned a particular technique. In this case, the aggregated data is appropriate, so based on the data of Example 11.9, it is better not to use the method.
The best treatment is not only a function of the data, but also of the assumed causality.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.